



Utiliser ChatGPT pour son contenu web, c’est se tirer dans le pied
Ce matin, une bonne amie me partage cette nouvelle et me demande ce que j’en pense.
« D’ici 2025, 90 % du contenu en ligne sera généré par l’IA »
Ma réponse fut: J’ai de gros doutes!
Voici donc une réponse plus détaillée…
ChatGPT est un outil qui a été développé à partir de contenus glanés sur le Web de 2020 à 2021. Il n’est donc pas « à jour » pour des contenus qui traiteraient de sujets contemporains. Par ailleurs, le programme de ChatGPT est conçu pour ne pas créer de contenus négatifs ou toucher à des sujets sensibles comme de la violence, le sexe ou des contenus considérés dangereux. De plus, ce logiciel a des biais le rendant incapable de prendre position. Il se doit d’être générique, sans danger, vrai et instructif. Il ne pourra donc pas décortiquer une situation réelle et présenter les pour et les contre d’une problématique. En outre, il ne présentera donc qu’un consensus de ce qu’il a collecté des contenus au moment de sa mise en ligne. Les consensus, comme c’est souvent le cas, évoluent dans le temps et peuvent changer drastiquement. Mais l’argument le plus important est que ChatGPT n’a aucune créativité. Il n’est pas capable d’être authentique, ce qui est la base même d’un contenu qui pourrait devenir viral ou simplement intéresser les lecteurs. Bien que j’étais spéciale durant mon enfance et que j’aimais lire les encyclopédies, on s’entend que c’est loin d’être le cas pour tous.
Utiliser ChatGPT et être pénalisé par les moteurs de recherches.
Disons que vous êtes un luthier et que vous utilisez chatGPT pour générer des textes pour votre site web. Les contenus que générera ChatGPT existent donc déjà sur le web. Il en fera une synthèse et vous la présentera. Imaginez aussi que l’un de vos compétiteurs a la même idée et génère lui aussi des contenus pour parler du même sujet. Il y a de fortes chances que vous soyez tous les deux pénalisés pour contenus dupliqués, ce qui est contraire à l’algorithme de Google entre autres. Vos contenus en plus de ne pas être authentique, ne seront donc pas non plus originaux.
Par ailleurs, selon searchenginejournal, les contenus générés automatiquement sont contre les directives aux webmestres de Google.
Automatically Generated Content Is Against Google’s Webmaster Guidelines
Regardless of the tools used to create it, content written by machines is considered automatically generated. As Mueller is quick to point out, Google’s position on auto generated content has always been clear:“For us these would, essentially, still fall into the category of automatically generated content which is something we’ve had in the Webmaster Guidelines since almost the beginning.
And people have been automatically generating content in lots of different ways. And for us, if you’re using machine learning tools to generate your content, it’s essentially the same as if you’re just shuffling words around, or looking up synonyms, or doing the translation tricks that people used to do. Those kind of things.
My suspicion is maybe the quality of content is a little bit better than the really old school tools, but for us it’s still automatically generated content, and that means for us it’s still against the Webmaster Guidelines. So we would consider that to be spam.”
Mais Google est-il capable d’identifier les contenus générés automatiquement?
ChatGPT travaille déjà et a promis d’inclure un filigrane « watermark » dans ses contenus, permettant d’identifier les contenus générés automatiquement. Par ailleurs, les recherches en ce domaine précèdent les innovations de ChatGPT. Cette preuve de tricherie, serait cachée dans des lettres, des mots ou des tournures de phrases, qui bien qu’ils apparaissant aléatoires à nos yeux, avec la clé cryptographique du propriétaire de ChatGPT, il serait aisé d’identifier le faussaire. Et ce, même s’il changeait certains mots pour tenter de faire passer un contenu généré automatiquement, par la création d’un rédacteur. Vous pouvez avoir les détails de cette procédure dans l’article de Techcrunch, OpenAI’s attempts to watermark AI text hit limits, It’s proving tough to rein in systems like ChatGPT.
Il y a certainement encore des débats sur l’efficacité ou non et l’approche propriétaire ou open source d’en tel filigrane, mais la conclusion de l’article de Techcrunch est sans équivoque. Tôt ou tard, les fourbes se feront pincer…
“You could worry that all this stuff about trying to be safe and responsible when scaling AI … as soon as it seriously hurts the bottom lines of Google and Meta and Alibaba and the other major players, a lot of it will go out the window,” Aaronson said. “On the other hand, we’ve seen over the past 30 years that the big internet companies can agree on certain minimal standards, whether because of fear of getting sued, desire to be seen as a responsible player, or whatever else.”
(notez que ce qui suit et est tiré de ChatGPT, sont des images et que leurs contenus sont donc invisibles aux moteurs de recherches. Si elles avaient des filigranes, ils seraient aussi invisibles…)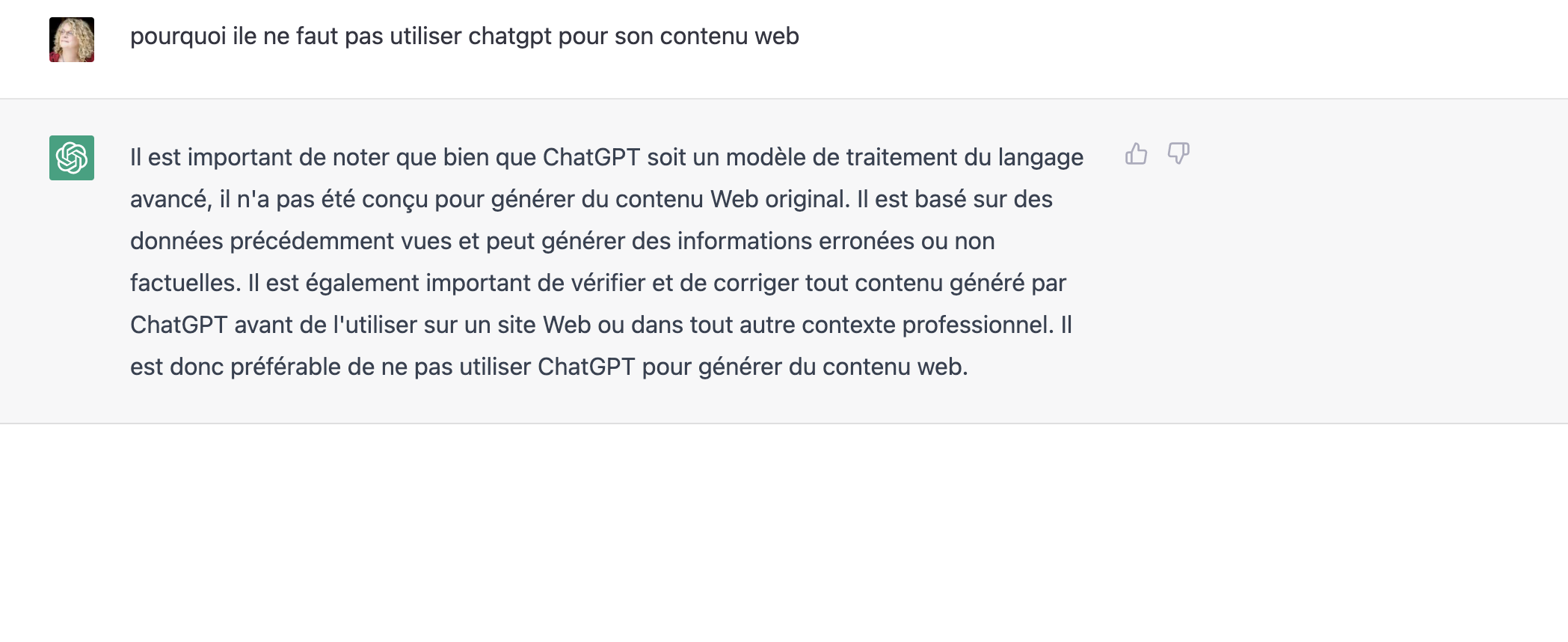

MAJ
Une nouvelle application Québécoise permettrais d’identifier les contenus autogénérés selon l’article La chasse au ChatGPT est ouverte. il s’agit de Detector https://detector.dng.ai/fr
MAJ2
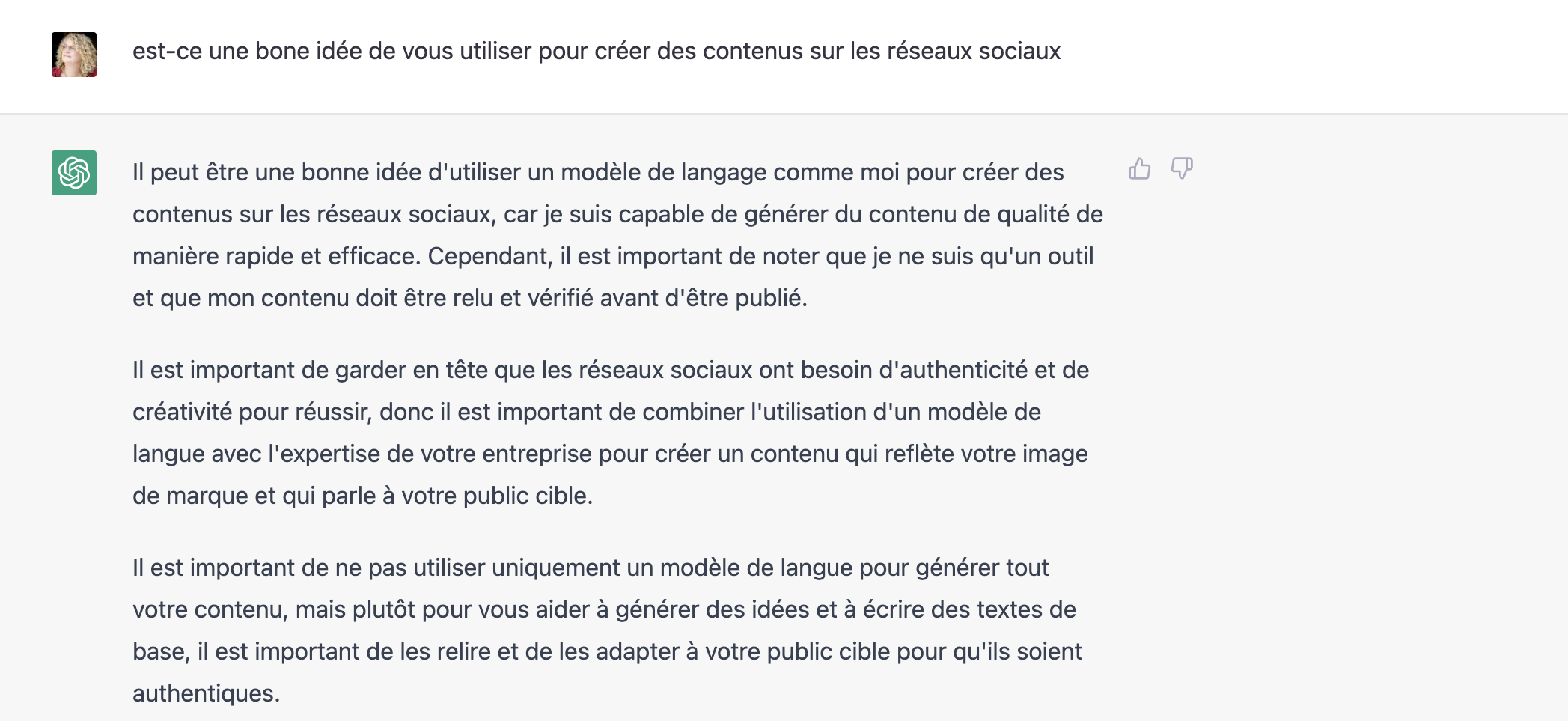
Le pote Yves William sur Facebook, demande à ChatGPT ce qu’il pense de ce billet. Voici le résultat…

Article publié le vendredi, 20 janvier 2023 sous les rubriques Blogue, Blogues d'affaires, ChatGPT, cybersécurité, Marketing de contenu, Moteurs de recherche et référencement de sites Web et stratégie de contenus.






