Archives pour hacking
C’est à la lecture d’un statut LinkedIn du pote Bernard Prince, que j’ai décidé de moi aussi mettre mon grain de sel dans les discussions autour de C-18 et du boycotte que fait déjà Meta (Facebook) et que fera probablement Google de ces mêmes médias. Mais avant de donner mon point de vue, je rappelle que pas plus tard qu’hier, les médias ont décidé de porter plainte au Bureau de la concurrence pour « abus de position dominante » par Facebook. Donc le nerf de la guerre pour les médias est l’accès à la publicité qui leur échappe depuis l’avènement massif des GAFAM.
Comme je l’écrivais en commentaire sous le statut de Bernard Prince :
Les hôteliers ont eu le même problème en l’an 2000 avec Hotels.com, Expedia et autres. Cependant eux se sont réveillés, pas les médias. Tu as tout à fait raison. Et le plus ironique, est que ces mêmes médias vomissent sur Twitter qui leur fait une pub gratis alors qu’ils valorisent à outrance Threads qui appartient à Meta et qu’une fois levée avec la super belle presse gratis de nos médias, feront comme ils ont fait avec Facebook et les banniras pratiquement de l’accueil des usagers…
Bernard a aussi ce commentaire :
Il y a effectivement un beau parallèle à faire! Un autre point à l’origine je pense, c’est la responsabilité de la plateforme face aux commentaires diffamatoires et les risques de poursuite. Au-delà de leur faire un pub gratis, les Meta, Twitter et autres ont aussi servi de sous-traitants pour la gestion des commentaires sur les nouvelles et chroniques.
Établir clairement le rôle et la limite de responsabilité d’un média VS la responsabilité personnelle de chaque internaute serait aussi une bonne façon pour les gouvernements d’aider ce secteur.
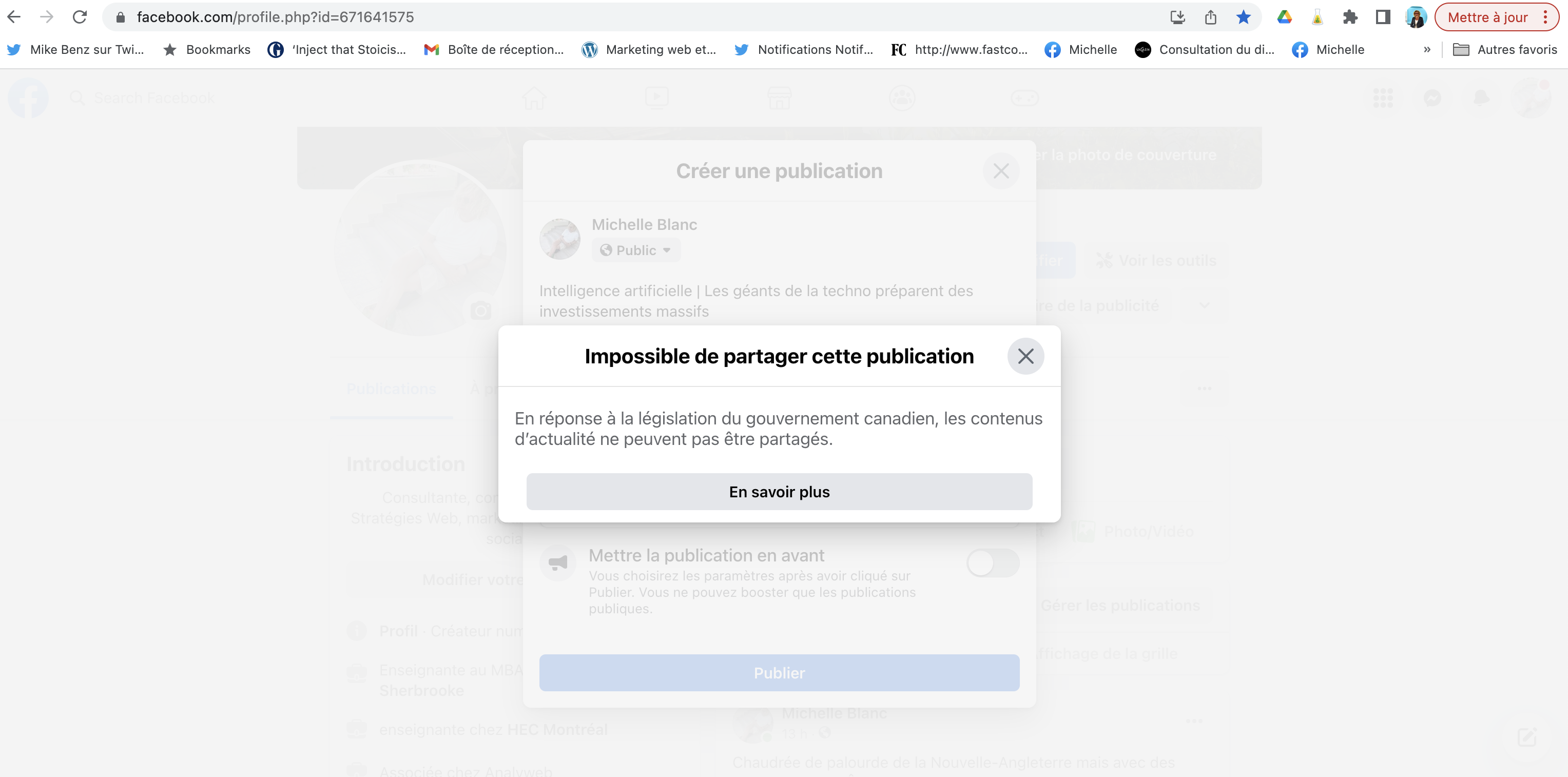
En résumé, tout comme la majorité des entreprises, lors de l’apparition de Facebook, tous disaient « Venez nous voir sur Facebook », plutôt que « Venez nous voir sur notre site web ». Cela a permis à Facebook de devenir gratuitement le Béhémoth qu’il est aujourd’hui. En outre, il est faux de dire que Facebook jouit des contenus médiatiques sur sa plate-forme. Il faudrait plutôt dire que Facebook permettait le partage des hyperliens médiatiques sur sa plate-forme, ce qui obligeait les usagers à cliquer et à aller sur les médias pour lire les contenus. Mais depuis ce matin, il ne m’est plus possible de partager ma revue de presse sur Facebook, qu’elle soit canadienne ou même internationale.
À propos de Google
Google a aussi menacé de retirer les hyperliens des médias canadiens de son engin. Mais au moment d’écrire ces lignes, il ne l’a pas encore fait.
Pourquoi Facebook et Google ont raison dans leurs positions?
L’ensemble des entreprises payent pour apparaître dans l’accueil des usagers de Google ou Facebook. Par contre, s’ils y mettent de l’effort, ils pourront apparaître dans les résultats naturels à l’aide des tactiques de référencement (ce qui n’est pas gratuit). En outre, les médias jouissent dans Google d’une visibilité accrue et gratuite dans la section actualité. Je rappelle aussi que ce sont les usagers de Facebook (et non pas Facebook) qui partagent les contenus des médias via des hyperliens. Ça donne donc du trafic au médias. Trafic qui ne leur coûte absolument rien. Il est donc tout à fait compréhensible que Google et Facebook refusent de payer pour du contenu qu’ils ne partagent pas eux-mêmes et qui de plus, permet une visibilité gratuite aux médias. À l’instar de tout autre type d’organisation qui se doit de payer pour une même visibilité. L’argument des médias est donc fallacieux.
Pourquoi les médias ont raison dans leurs positions?
Il est vrai que les médias souffrent énormément de la fuite des capitaux publicitaire de leurs plateformes, vers le numérique et en particulier vers Google et Facebook. Il est aussi vrai que le gouvernement se doit de faire quelque chose. Cependant, je ne crois pas que d’attaquer Facebook et Google soit la bonne solution. D’autant plus que l’offre publicitaire des médias est déficiente depuis de très nombreuses années et que comme le mentionne Bernard Prince, leur incapacité à s’adapter aux changements numériques est de leurs fautes, de leurs très grandes fautes. En outre, si jamais Google et Facebook devaient capituler, les médias ne récolteraient que des miettes. Quelques dizaines de millions au plus. Le réel problème de la fuite des capitaux publicitaire vers le numérique est la grande facilité à acheter de la pub et l’adage selon lequel « on peut réellement tout mesurer sur le web ». Cela était tout à fait vrai à mes débuts, il y a plus de 20 ans. Ce n’est plus le cas aujourd’hui. La pub numérique est maintenant gangrenée de fraude à grande échelle. Plus de 50% des pubs numériques ont des vues et des clics frauduleux. Des milliards de dollars de publicité alimentent les réseaux de trafic d’armes, de pédopornographie, de pornographie, de terrorisme et autres problèmes mondiaux majeurs. Google et Facebook ne sont pas responsables de ça, mais ils n’ont aucun intérêt à se couper de 50% de leurs chiffres d’affaires. Car, plus de 50% de la pub numérique est frauduleuse. C’est le plus grand crime internet non criminalisé. Si les médias traitaient intelligemment de cette question et instruisaient les entreprises de cette réalité, les milliards ainsi détournées reviendraient dans leurs propres coffres. Pour cela, il suffirait que le gouvernement criminalise la fraude publicitaire, qu’il développe les outils et processus pour vérifier ces fraudes et qu’il poursuive les auteurs.
Vous croyez que j’exagère?
Il vous suffit de lire ma référence dans le domaine, le Dr. Augustine Fou de NYU. Depuis plus de 30 ans, il traque les pratiques douteuses des fraudeurs et de l’ANA (Association of national Advertisers), des soi-disant entreprises de détection de « bots » et des agences qui joueront les vierges offensées si la question leur est soulevée.
Vous pourriez aussi aimer
Petite histoire des mensonges des GAFA et des autres médias sociaux
Forbes: What Your Fraud Detection Vendor Misses
Percent Fraud is the Wrong Way to Assess Quality. Use Percent Human Instead
What Helped Digital Ad Fraud Spread Like a Disease For A Decade?
L’alternative à l’endémique fraude par clic
La fraude publicitaire en ligne est le crime numérique le plus payant, aperçu de la cybercriminalité
Article publié le mercredi, 9 août 2023 sous les rubriques Commerce électronique: mythes, cybercriminalité, Facebook, hacking, Marketing de contenu, Marketing Internet, marketing mobile, Medias et Internet, stratégie numérique et transformation numérique.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Bill C-18, Fraude par clic, fraude publicitaire, Google +, Meta.
Dans mon récent billet La mauvaise idée pour les entreprises, du code QR comme outil d’identification du certificat de vaccination, j’expliquais pourquoi il sera dangereux pour les entreprises de vérifier le code QR de leurs clients. Maintenant je vais vous expliquer Comment vérifier les passeports vaccinal sans compromettre la sécurité de vos infrastructures numériques?
Au moment d’écrire ces lignes et comme suite à l’annonce du ministre de la Santé Christian Dubé, nous savons maintenant qu’à partir du 1er septembre, les entreprises auront le fardeau de devoir vérifier le code QR de leurs clients avec une application numérique gouvernementale développée à cet effet. Selon de JdeM :
Code QR et pièce d’identité
C’est sur une application mobile gratuite que le passeport vaccinal sera rendu disponible, a expliqué le ministre de la Santé. Les citoyens qui n’ont pas de téléphone pourront aussi présenter leur passeport en format papier. Les utilisateurs devront montrer leur code QR dans les lieux qui requièrent le passeport et il faudra également présenter une preuve d’identité avec photo.
Au moment d’écrire ces lignes, nous savons encore très peu de choses sur l’application gouvernementale devant permettre aux entreprises de vérifier le code QR de leurs clients. Nous savons cependant qu’il s’agira bien de devoir lire un code QR et que cette action, tel que démontré dans mon précédent billet, une porte grande ouverte pour compromettre les infrastructures numériques des entreprises.
La solution sécuritaire pour lire le code QR des entreprises
La manière la plus sécuritaire de lire le code QR des clients des entreprises sans compromettre la sécurité de son infrastructure informatique est de s’assurer que le lecteur de code QR, soit dans un environnement complètement externe à celui de l’entreprise. Pour ce faire, vous devriez acheter des téléphones intelligents les moins dispendieux possibles et ne télécharger sur ceux-ci que l’application de lecture de code QR qui sera fourni par le gouvernement. Deuxièmement, ce(s) téléphone(s) devraient se brancher à un dispositif wi-fi complètement indépendant du reste de votre infrastructure numérique et de vos connexions internet. Comme ça, si jamais un de vos clients tentait d’hameçonner vos systèmes, il sera dans un environnement vide et complètement coupé de votre infrastructure qui elle sera épargnée des intrusions possibles. Voilà.
MAJ
Sur Facebook on me pose une question:
-Question et pour nous qui serons obligés de le faire Comment on protège nos données personnelles? merci
-côté citoyen ou entreprise?
-côté citoyen
-Utilisez un code QR papier au lieu de l’application et pour les données personnelles de santé derrière le code QR, il est trop tôt pour se prononcer et de toute manière, vous n’avez aucun contrôle là-dessus, malheureusement…
Article publié le mercredi, 11 août 2021 sous les rubriques cybersécurité et hacking.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Code QR, passeport vaccinal.
Lors de mes études de marketing internet, mon professeur Jacques Nantel nous parlait de l’un des problèmes de la personnalisation numérique dans un contexte de commerce en ligne. Si je vais acheter une cuvette de toilette parce que la mienne est brisée, j’aimerais bien que chaque fois que je visite un site transactionnel de quincaillerie, qu’on ne me présente pas la plomberie de facto. Pareillement, si j’achète un livre de comptine pour mon petit-fils, je souhaiterais ne pas me faire bombarder de pubs de livres pour enfants. Il est un peu là le problème majeur du remarketing et du retargeting.
Qu’est-ce que le remarketing et le retargeting?
Dans un billet de 2016, Le remarketing (reciblage publicitaire) ou comment exaspérer ses clients passés ou futurs, j’expliquais déjà le problème « d’exaspération » des internautes qui ont l’impression d’être suivi sur le Web. Mais à l’époque, je croyais encore que ça pouvait être une tactique rentable pour les entreprises. Je ne voyais pas encore tout l’écosystème de fraude dont ces techniques étaient tributaires. En fait, le remarketing est un système basé sur des « cookies » (un témoin numérique qui s’installe sur votre ordinateur lorsque vous visitez un site transactionnel) qui va vous présenter des pubs avec la rationale que si vous avez visité une page de produit, c’est probablement parce que vous êtes acheteur et que vous devriez être relancé.
Or, comme je l’expliquais dans le billet cité, j’étais déjà acheteuse puisque j’avais acheté. Je n’avais donc pas besoin d’être « vendu de nouveau ». En outre, il y a plusieurs raisons pour lesquelles j’ai peut-être visité une page de produit. Peut-être étais-je en train de comparer les prix et que le vôtre était trop élevé, peut-être que comme l’exemple ici-bas, que je voulais me rendre compte à quel point le vendeur est «dans le champ » et que jamais je n’achèterais son produit. Mais là où le bât blesse est que 50% de l’argent que vous y dépenserez, y sera carrément frauduleux à cause de tout un écosystème dont le but est de faire croire à des visites, des pages vues, des clics et des conversions. C’est ce qu’explique le Dr Fou (dont j’ai déjà parlé ici) dans son article When Retargeting And Re-Marketing Become Re-Annoying:
Further, research from mFilterIt this week, a performance fraud prevention specialist confirms the levels of bot activity and fraud in retargeting, re-marketing, and affiliate marketing campaigns. “Average fraud levels are in the 40-50% range, with highs of 99% fraud seen regularly.” The bots used in these kinds of campaigns are fake devices. They love getting lots of impressions. They love getting retargeted after they deliberately visit ecommerce sites. Retargeted ad CPMs are often higher than other display ads so they earn more for every impression they cause to load on a cash-out site. Many of the remarketing campaigns are paid for on a CPC (cost per click) basis. That means the marketer only pays when they get the click. That also means the bots only get paid when they click. So they click. A lot.
C’est aussi l’avis de Alex Czartoryski dans l’article Attribution Poaching and Remarketing Fraud :
To be clear, these sites are not actually serving any visible ads to any users. They are generating fraudulent ad impressions to set cookies on as many users as possible in order to “poach” conversion attribution (and budget) from your other channels. If a user with their cookie ever makes a purchase in the future, that site will get a view-attribution for that purchase, causing more ad budget money to flow to them.
All these hidden impressions distributed to as many users as possible cause View Through Conversion metrics to skyrocket. As mentioned before, View Through Conversions reported by an ad platform can easily be more than 10 times the number of Click Through Conversion reported. It is no surprise that ad platforms want you to believe in and count View Through Conversions.
Vous pourriez par contre faire comme Lego et plusieurs autres et à la place de dépenser de l’argent sur des pubs frauduleuses, miser sur le marketing de contenu qui a une pérennité d’investissement puisqu’une fois en ligne, les contenus perdureront.
Exemple d’un processus de remarketing complètement inutile
je partage un statut Facebook

On me fait un commentaire avec un hyperlien
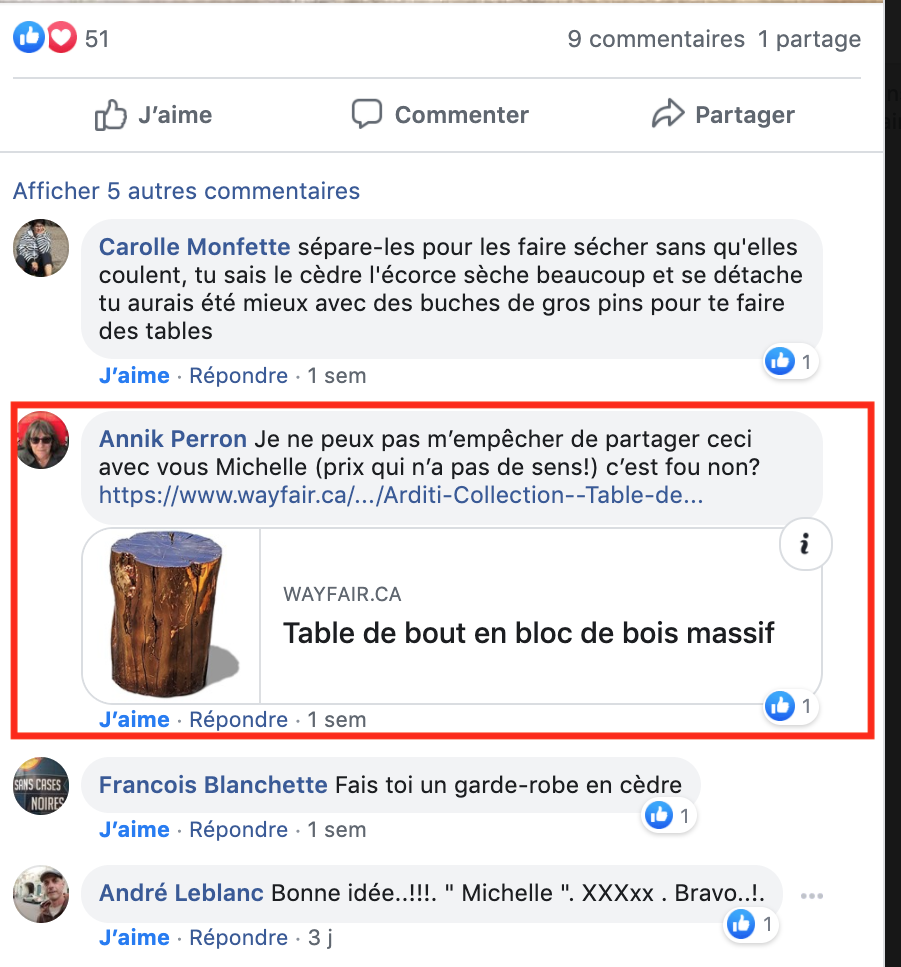
Je visite le site

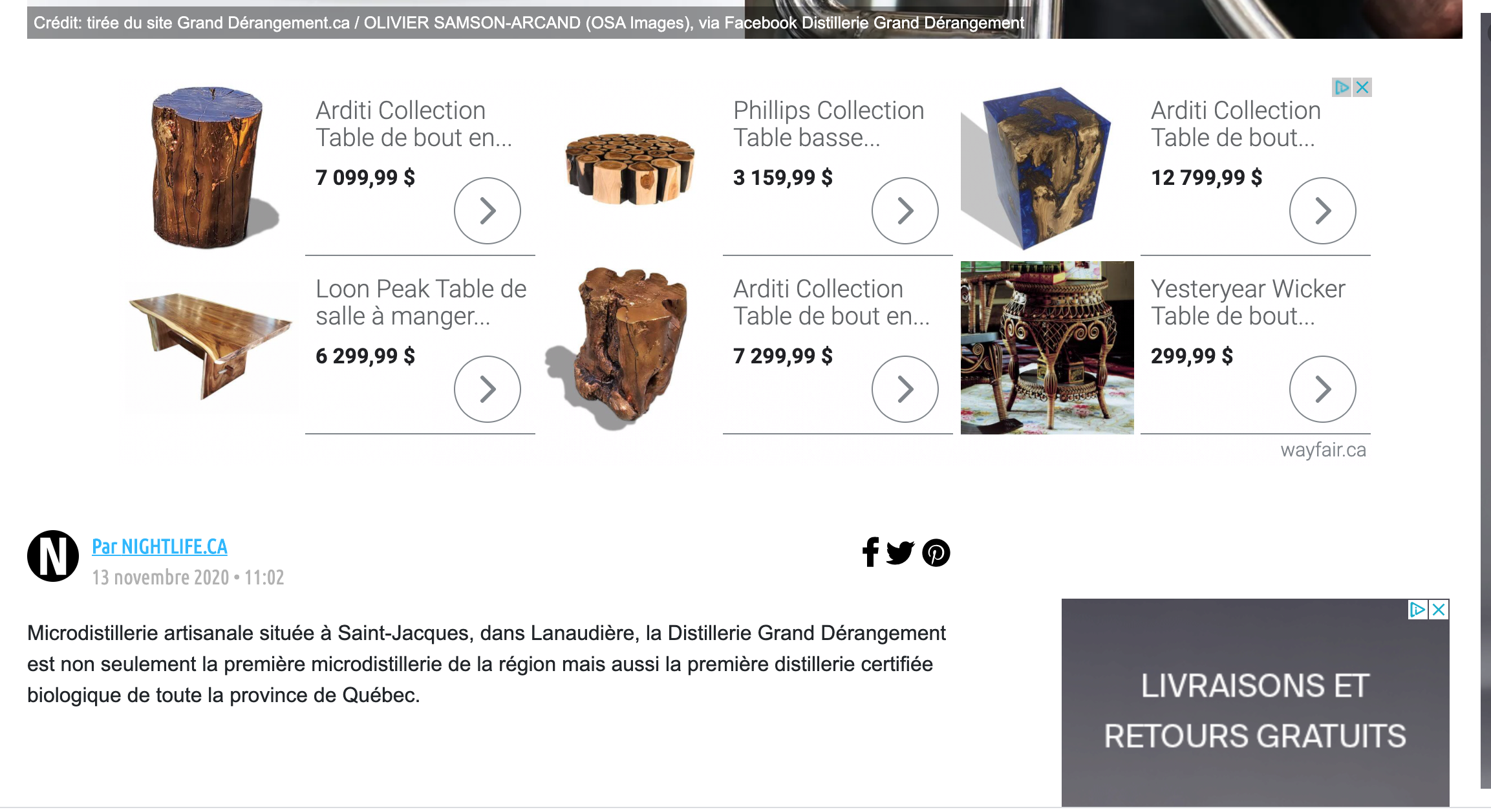
On me sert une pub de remarketing
Sources et lectures complémentaires:
Le blogue et le marketing de contenu, plus pertinent que jamais
Lego, un exemple éloquent et extrêmement rentable du marketing de contenus
Attribution Poaching and Remaketing Fraud
When Retargeting And Re-Marketing Become Re-Annoying
Fake, fake, fake: Epic tweetstorm targets marketing’s metrics house of cards
The Alleged $7.5 Billion Fraud in Online Advertising
Article publié le lundi, 16 novembre 2020 sous les rubriques Commerce électronique: mythes, cybercriminalité, Facebook, hacking, Marketing de contenu, Marketing Internet, marketing mobile et Médias sociaux.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : fraude publicitaire, remarketing, retargeting.
“It’s easier to fool people than to convince them that they had been fooled.” Mark Twain

Dans mon billet La pourriture marketing web Partie 2 (fraude par clic), j’exposais les découvertes à propos de la fraude par clic du Dr Augustine Fou. Depuis, il a fait plusieurs autres publications donc son Fake everything 2019. Il n’hésite d’ailleurs pas à traiter l’ANA (Association of national Advertisers) et l’industrie publicitaire d’incompétents.
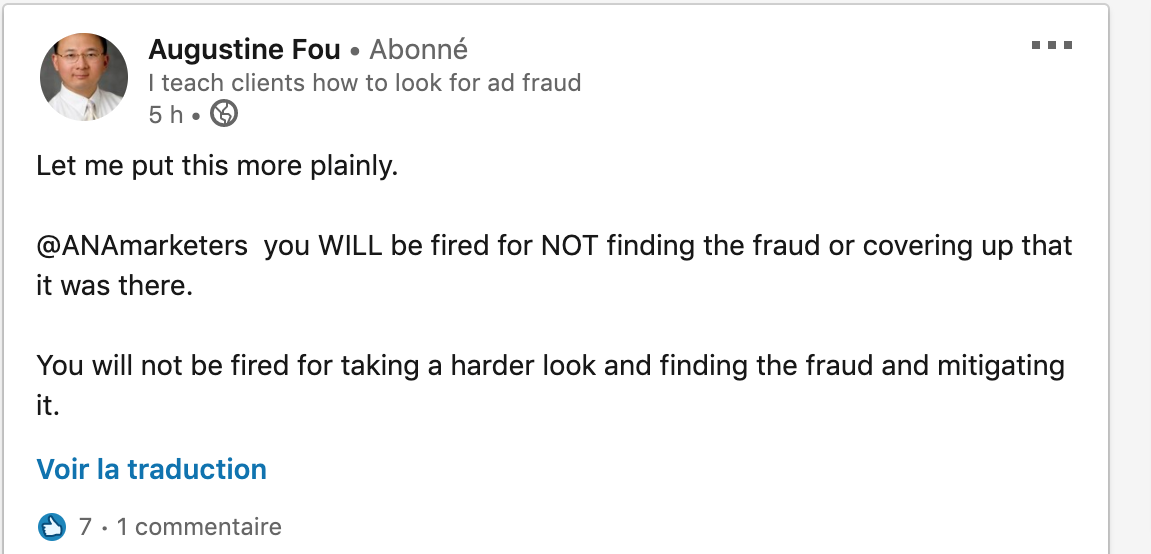
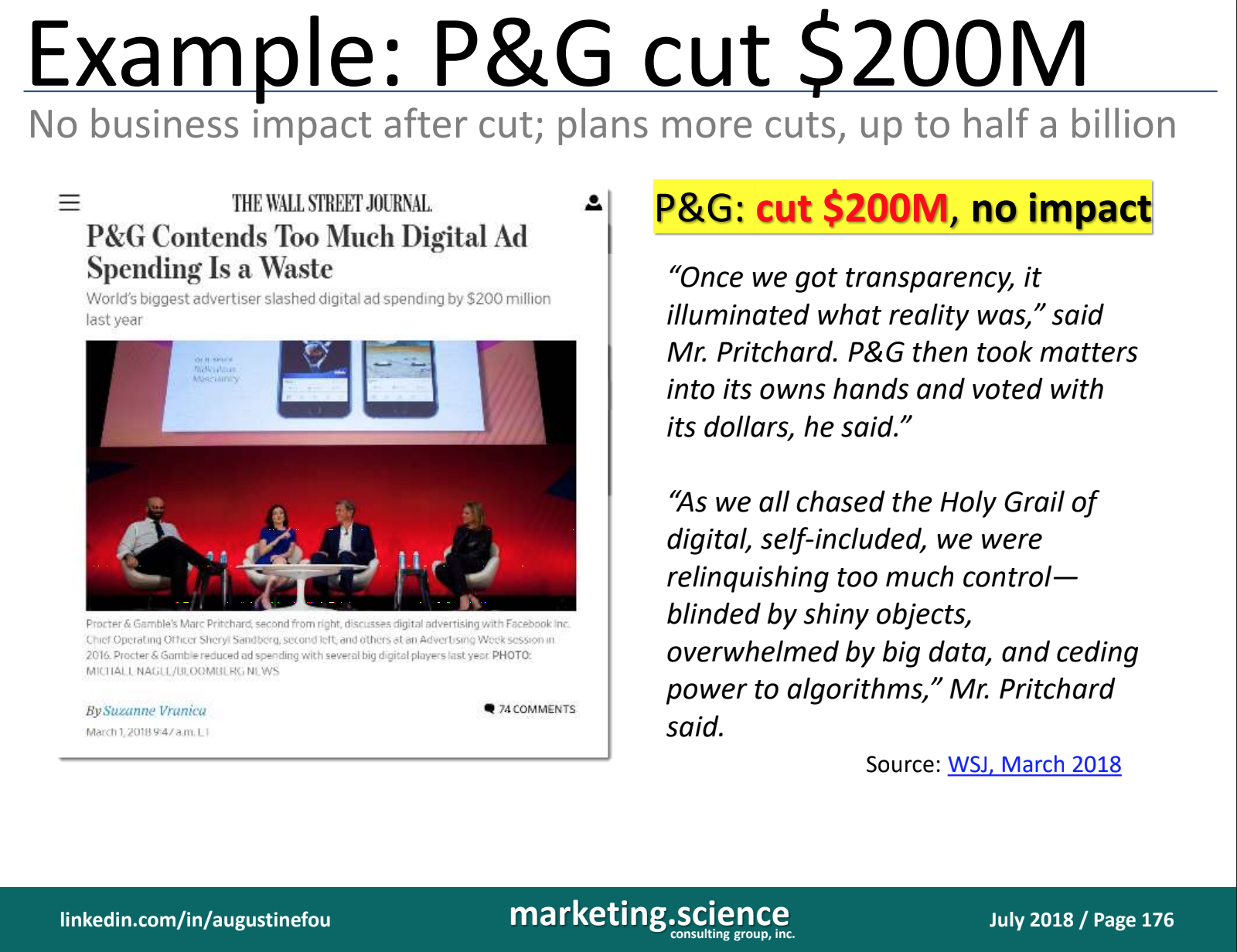
À la lecture des observations du Dr Fou, les preuves de l’ampleur de ces fraudes sont indiscutables. C’est d’ailleurs tellement répandu et connu de plusieurs, tant des publicitaires, des agences que même des clients, qu’il est aberrant de constater que ce soit la plus lucrative des activités cybercriminelles et pire encore, que ce soit encore tout à fait légal (ou plutôt, non encore réglementé). D’ailleurs, l’ironie ultime de cette arnaque de grande envergure est l’exemple de Procter and Gamble comme je le citais dans mon dernier billet :
L’ironie du sort est cette nouvelle de AdWeek qui présente que Procter and Gamble en coupant $200 millions de publicités numériques, a augmenté sa portée de 10% 🙂
Comment continuer à rejoindre ses clients sans tomber dans la fraude et encourager les arnaqueurs?
1- Valoriser le marketing de contenu et vos propres propriétés web
2- Valoriser le trafic naturel et la longue traîne
3- Valoriser la publicité traditionnelle (journaux, radio, tv, panneaux routiers) et idéalement en mode écoute en direct (Météomédia, sports, grande écoute en live)
4- Valoriser la publicité numérique strictement sur les plateformes des éditeurs numériques reconnut et que vous savez qu’ils ont pignon sur rue et qu’ils sont visités par de réels internautes (médias en ligne, sites spécialisés, site web sérieux que vous connaissez et visitez, blogues reconnus)
5- Faite de la commandite
6- Faite de la publicité en point de vente
7- Faite de la publicité événementielle




Mon changement de perspective
À mes débuts, il y a près de vingt ans, je valorisais grandement le Web étant donné qu’on pouvait tout mesurer contrairement à la pub traditionnelle qui était une création de l’esprit. Je suis toujours de cet avis avec de grosses nuances. J’aimais dire que si on écoutait une émission de grande écoute (disons Tout Le Monde En Parle) et qu’on vendait le 1 million d’auditeur, on payait pour ce million d’auditeurs mêmes si plusieurs se levaient lors des pauses publicitaires pour faire autre chose ou que comme moi, ils enregistraient l’émission et débutaient son écoute un peu plus tard en accélérant les pauses publicitaires pour ne pas les voir. C’est toujours le cas. Sauf que sur le million d’auditeurs, un pourcentage non défini regardera tout de même la publicité et que si on peut mesurer sa conversion, ça peut toujours valoir la peine. Il en est de même des autres supports traditionnels.
J’ai toujours eu de la difficulté avec la pub comme telle. Qu’elle soit en ligne ou hors-ligne. J’ai toujours valorisé le marketing de contenu et le trafic naturel qu’on nomme aussi « own media ». C’est plus de travail, mais beaucoup moins dispendieux. En outre, ça offre une pérennité à l’investissement puisqu’une fois que c’est en ligne, ça y demeure même si on coupe le budget publicitaire. Mais il est vrai que c’est plus de travail et que c’est plus difficile. Quoi qu’il en soit, étant donné l’ampleur des arnaques de fraude par clic, de trafic invalide et acheté et de la programmatique qui semble maintenant érigé en système, il m’apparaît de plus en plus évident que mon instinct et que mon sens moral antipub, est de plus en plus judicieux. C’est donc à vous de faire vos choix…
Les sources:
https://www.linkedin.com/in/augustinefou/
https://drive.google.com/file/d/1r3g4GwBTl0hxh6RI97zxwCVErlrYauu8/view
Article publié le jeudi, 13 février 2020 sous les rubriques cybercriminalité, cybersécurité, Droit et Internet, Economie des affaires électroniques, Facebook, hacking, Marketing de contenu, marketing mobile, Médias sociaux, Medias et Internet, Mobilité, Moteurs de recherche et référencement de sites Web et Web mobile.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Association of national Advertisers, Augustine Fou, Fraude par clic, Meteomedia, Procter and Gamble.
Ce billet est la suite du précédent billet La pourriture marketing web Partie 1
Votre site est l’étoile de votre système solaire
C’est le pote Jacques Warren qui sur LinkedIn, à la suite de mon partage de l’article The Role Of A Website Today me fit parvenir la baladodiffusion Ad Fraud with Dr. Augustine Fou du site Analyticshour. Dans l’article de Forbes, l’auteur écrivait ce que Jacques et moi-même disons depuis une vingtaine d’années. La présence web la plus importante de toutes stratégies numériques est votre propre site Web. Toutes vos autres présences sociales et activités de marketing numérique ne devraient avoir qu’un seul objectif, celui de faire cheminer un internaute vers VOTRE propriété internet et le pousser vers la conversion, c’est-à-dire de le faire acheter, demander une soumission, vous contacter ou remplir un questionnaire.
Don’t simply hire the local hipster you met at the coffee shop to create your business website. You wouldn’t do that to fix your car, so why would you do that with something so important to your business? Make sure your website developer has SEO, marketing, lead generation and programming knowledge because your competitors likely will.
Your website is the mother ship; it’s where all the important information is exchanged and where the most important digital actions take place. It’s not something to be taken lightly, and it’s not something to skimp on.
Mais l’auteur conseille aussi de travailler avec des gens qui savent ce qu’ils font et ne sont pas le “hipster local” ou le beau-frère qui prétend connaître le domaine parce que très possiblement vos compétiteurs eux, engageront des ressources compétentes.
La fraude par clic
(vous pouvez lire mes billets de 2006 sur le sujet
Fraudes par clic, Yahoo condamné à son tour, Google et Yahoo se font ramasser pour les fraudes par clic)
Pour revenir à la baladodiffusion citée plus haut, il s’agit en fait d’une entrevue avec le Dr Augustine Fou. Titulaire d’un PhD de MIT et professeur de marketing à Rutgers University and NYU, en plus d’avoir été consultant pour certaine des plus importantes entreprises de consultation de la planète, qui s’est intéressé et a décortiqué en profondeur le très vieux problème de la fraude par clic. À mes débuts, il y a de nombreuses années, on parlait déjà de 20% des budgets de publicité numériques qui étaient en fait de la fraude. Puis on parla plus récemment de 30 puis de 50%. La blague étant même “que 50% des budgets de placement de publicité numériques sont de la fraude, mais on ne sait pas lequel des deux 50% est le bon”. C’est tout dire. Mais avec l’avènement de la programmatique, selon le Dr. Fou, ce pourcentage de dépenses frauduleuses monterait maintenant à 90%, dans certains cas. C’est difficile à croire et ce sera sans doute un choc pour plusieurs lecteurs, mais ses explications sont des plus réalistes et documentées. La pub numérique serait donc une machine à imprimer de l’argent frauduleusement.
Pour vous en convaincre, voici des extraits de cette discussion de plus d’une heure et que vous pouvez écouter intégralement ici https://www.analyticshour.io/2019/09/10/123-ad-fraud-with-dr-augustine-fou/
(…)
And with the rise of programmatic, we started seeing things like 30% click-through rates, 50% click-through rates, 0% bounce rates, and things like that. And so all of those were strange. Those don’t make sense because humans are just not that interested in your damn ad.
(…)
And over the years, there’s some young marketers coming out that don’t have the experience to know that click-through rates on banner ads were supposed to be in the 0.1% range, and search ads in the 1% range. When you see 30% click-through rates, something’s wrong with that. So they don’t have that common sense that something is strange ’cause that’s been the norm that they’ve been seeing.
(…)at just doesn’t do anything to damage my assumption that agents, that media agencies are not incentivized to actually ferret out ad fraud.
(…)So think of the ad exchanges. They make more money when there’s more volume that passes through their exchange. So anything like ad fraud, if we discover that 50% of the volume is fraudulent, they would be making a lot less money. So some are simply looking the other way because they’ll say, “It’s not our job to look for that. It’s your job as a marketer. If you wanna waste the money, it’s your problem.”
(…) Literally, they are glued they might as well have a third arm holding the phone in front of their faces, 6 inches away from their face for 24 hours a day, including when they sleep. And that even that can’t account for all of the trillions upon trillions of ad impressions that were purportedly trading in digital marketing these days.
(…)And the one thing I think that a lot of people in the group that didn’t work in data and marketing, couldn’t understand, was how do the fraudsters actually get money out of it?
(…)
Think of a whole bunch of computers, compromised with malware, or laptops or now, smartphones. There’s 10 times more smartphones than there are computers. And furthermore, the smartphones are left on 24/7, as opposed to computers or laptops, which you turn off at night.
0:16:17 DF: So when you have all these smartphones that can be remotely controlled by a bot master, you can now have millions and millions of devices that do certain things. So you could say, go hit this one website with so much traffic that it can’t come up anymore or you can point that traffic firehose to a site that has ad tech on it. So when there’s ad tech on it, it will start showing ads every time you load the webpage. And so, that’s how the early bots started to make money, by generating ad fraud. All they had to do was cause the page to load and then all these ads would load. And think about sticking five ads on the page or 10 ads on the page. Or if you’re really unscrupulous, 1500 ads on the page. So on and so forth, right?
(…)
But kind of tying this back to the ad fraud, those sites have no traffic. So, they would just go out and buy all their traffic. And it’s a very simple arbitrage, right? If you buy your traffic for $1 and you sell your ads for $2, you’ve just made 100% profit. Pure profit. And there’s many, many variations. Sometimes you buy the traffic for a dollar, you can sell your ads for $10. Now you’ve made a 9 X markup. So some of my studies in that 2018, q2 ad fraud deck, you can see 25 X return. 42 X return. That’s not 42%, that’s 4200% return, for every dollar you spend in digital ad fraud. So why wouldn’t you spend the next dollar, to then make $42?
(…)Oh, yeah. Well, I’m in charge of $30 million of spending in digital.” So they will have to spend it all. If they don’t spend it all, they risk losing some of it, right? They won’t have as much to spend next year, so they will find every means to spend it and also find the means to make sure everything looks right. So they will buy those fraud detection reports that specifically say, “There’s no fraud, don’t worry about it.” Alright, so that provides them air cover, so that they can continue buying that. Even if some boy scout showed them the data that, “This is all fraudulent, you know that, right?” They’ll say, “Don’t tell anyone. We wanna keep buying.”
(…)
Ad front is not a tech problem, it’s an incentives problem, and that goes all the way up to the marketer themselves, the parties that are spending them, the dollars.
(…)
And there was a recent study I tweeted within the last week or so that there’s another larger study that showed, and this was interview, so I wouldn’t put too much weight on it, but marketers, like more than half of them, said digital marketing, especially programmatic display and all that kind of stuff, didn’t generate any noticeable business outcomes, and that was being kind. It was a complete waste of money, but they put it in the sense that it didn’t generate any noticeable business outcomes. Of course, you didn’t notice anything, because it didn’t do anything.
(…)
It’s a game of finding out which clients actually care to hear what we have to say.
J’ai toujours refusé de faire de la pub numérique pour mes clients. Depuis le temps, je sais qu’une portion très importante de leur argent servira à faire vivre un système plutôt que de générer de la conversion. Je préfère de loin la pérennité de peurs investissements via le marketing de contenu. C’est plus de job et moins de fric pour les agences, c’est donc moins sexy et pas mal moins payant pour moi. Mais le soir, lorsque je me couche, je dors beaucoup mieux…
Épilogue
La crise des médias n’est pas que le fruit d’une incompétence de certains éditeurs à s’adapter. Elle est aussi la résultante des décideurs marketing à investir dans des pubs internet qui ne vendent que du vent…
Vous pourriez aimer lire
Legal Cases Documenting Details of Fraud
What The Hell Happened to Good Publishers 1995 2015
State of Digital Ad Fraud Q2 2018
6 Months After Fraud Cleanup, AppNexus Describes Impact On Its Exchange
Calling Bullshit, Data Reasoning in a Digital World
Article publié le vendredi, 4 octobre 2019 sous les rubriques Commerce électronique: mythes, hacking, Marketing Internet, marketing mobile et Medias et Internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Fraude par clic, Marketing de contenu.
C’est la semaine dernière que Monsieur Éric Caire, ministre délégué à la transformation numérique gouvernementale, a déposé le projet de loi 14 (PL-14) Loi favorisant la transformation numérique de l’administration publique. Selon le communiqué de presse du gouvernement, ce projet de loi vise à :
(…) à faciliter la mise en place de services numériques plus conviviaux et mieux adaptés aux besoins des citoyens. Il rend possible le partage d’information entre les ministères et organismes, lorsque la situation le requiert, pour améliorer la fluidité des services et simplifier l’accès aux solutions numériques gouvernementales.
Le projet de loi garantit la protection des renseignements personnels à toutes les étapes de la réalisation des projets numériques. Seuls les organismes publics spécialement désignés par le gouvernement seront autorisés à partager des renseignements personnels entre eux. L’utilisation de ces données est strictement limitée à la réalisation d’un projet d’intérêt gouvernemental, et ce, pour une durée fixe que la loi vient préciser.
C’est une étape importante et essentielle pour le développement éventuel de services gouvernementaux numériques dignes de ce nom et pour une saine prestation de service interministérielle. J’applaudis le gouvernement d’avoir fait ce premier pas. Par contre, à la lecture des prochains paragraphes, vous conviendrez comme moi qu’il s’agit en fait du strict minimum. J’imagine et je souhaite sincèrement que ce ne soit QUE le premier pas et que d’autres projets de loi viendront combler ce qui m’apparaît comme des lacunes importantes.
Les manquements évidents du PL-14
Depuis quelques années déjà, les entreprises sont soumises à la Loi sur la protection des renseignements personnels et les documents électroniques (LPRPDE) qui touchent les organisations et entreprises fédérales. En gros, ils doivent colliger les informations personnelles des consommateurs dans des banques de données spécifiques, nommer une personne responsable à la face du public, maintenir l’intégrité de ces mêmes données, offrir la possibilité aux consommateurs de vérifier l’exactitude de ces données et de les faire modifier si besoin et même de les effacer si tel est son choix. De plus, les entreprises seront scrutées à l’externe et s’exposeront à des amendes pouvant être très salées, s’ils ne se conforment pas correctement à cette loi fédérale. Voici d’ailleurs les 10 principes de cette loi.
-
- Responsabilité
- Détermination des fins de la collecte des renseignements
- Consentement
- Limitation de la collecte
- Limitation de l’utilisation, de la communication et de la conservation
- Exactitude
- Mesures de sécurité
- Transparence
- Accès aux renseignements personnels
- Possibilité de porter plainte à l’égard du non-respect des principes
Disons qu’à la lecture du PL-14, nous constatons que le gouvernement du Québec sera vraiment très loin de ces principes qui doivent assurer une certaine pérennité du consentement du citoyen, de la vérification de l’exactitude, de la limitation de la collecte, de la sécurité, de la transparence, de l’accès, de la permission et des mécanismes de plaintes et des conséquences éventuelles de ces plaintes.
Sur mon LinkedIn dans lequel je partageais cette loi, un abonné écrivit à propos de celle-ci
Suis allé lire le projet de loi. Que dire? Épeurant de vacuité par rapport à ce qui se fait ailleurs dans les pays occidentaux en matière de collecte et partage de renseignements personnels au sein des organismes publics. Rien sur le consentement éclairé des citoyens, rien sur les nouveaux renseignements personnels (biométrie et génétique). Où est le pendant pour protéger les citoyens des dérives de l’industrie privée. Seul point positif, le CT est responsable de l’application.
Par ailleurs, je comprends un peu le bourbier dans lequel se retrouve notre gouvernement. Afin d’être capable de satisfaire aux principes que notre gouvernement fédéral demande pourtant aux entreprises canadiennes, le gouvernement devrait à tout le moins avoir une gestion centralisée de ces données, ce qu’il n’a pas, et de gérer convenablement ces mêmes données, ce qu’il ne semble pas faire non plus. Dans le plan numérique du PQ que j’avais proposé, on parlait entre autre de l’architecture X-Road pour permettre de régler certains des problèmes de partage des données gouvernementales, tout en respectant la vie privée et le choix des citoyens de partager ce qu’ils veulent bien.
On parle ici de l’architecture X-Road. Créée en Estonie, l’architecture X-Road permet aux services publics du pays de s’interconnecter afin d’échanger leurs données pour faciliter la vie des citoyens. Ce modèle a permis une coopération plus poussée entre les organisations publiques et a réduit l’utilisation du papier de façon importante. En prime, les employés de l’État peuvent désormais se concentrer sur les tâches qui nécessitent des interactions humaines. Il s’agira, pour nous, d’observer ce qui se fait partout sur la planète et de retenir les solutions qui s’appliquent le mieux chez nous.
D’ailleurs, récemment le gouvernement suggérait de migrer ces données dans le « cloud » d’une des multinationales américaines avec un appel d’offres. En plus d’être un aveu d’échec cuisant de l’infrastructure des données actuelles, ça permettrait de « pimper nos données ». Lorsque j’écris ça, je ne me réfère pas à l’expression qui a le sens d’amélioration, mais plutôt à celui qu’on prostituerait nos données sensibles à un pimp qui par la suite nous ferait chèrement payer pour l’accès granulaire et intelligent de ces mêmes données. Ce qui est tout à fait scandaleux.
Données ouvertes
Dans ce document on ne dit strictement rien sur les données ouvertes ni sur la protection des données personnelles dans les contextes municipaux. On n’y parle pas non plus de l’intelligence artificielle, de la biométrie et de toutes les avancées aussi spectaculaires qu’inquiétantes que ces mêmes données permettent désormais.
Prédation des données sur le domaine public
Saviez-vous que présentement, certaines entreprises canadiennes et québécoises offrent aux municipalités canadiennes des mobiliers urbains intelligents? Ces mobiliers permettent entre autres d’enregistrer vidéo-voix-données, des usagers qui s’en servent et des passants qui circulent autour. Moi j’ai pogné un méchant buzz en apprenant ça. D’ailleurs, je sais que certains dirigeants TI de municipalités ont été outrés de tels avancés et de réaliser que ces informations étaient retransmises, sans filtres, aux fournisseurs qui proposaient ces mobiliers. Il en est de même pour les feux de circulation intelligents qui scannent les adresses MAC qui se trouvent dans un rayon de 200 mètres de ces feux, puis revendent ses informations au plus offrant, sans que personne ne s’en inquiète. Il me semble qu’il y a là une méchante matière à légiférer. L’un des exemples éloquents des dérives possibles de ce laisser-aller législatif au profit de « bienfaiteurs intelligents et de fournisseurs de gugus de données » est l’exemple récent de Sidewalk Toronto. Un projet de ville intelligente parrainée par la bienfaitrice Alphabet, maison mère de Google. Ce projet est une « expérience » de l’établissement d’un quartier intelligent en bordure du Lac Ontario à Toronto. Il permettra à Google de recueillir et de gérer les données faciales, télémétriques, de circulation et de toutes autres données qu’il jugera importantes, sans l’autorisation des citoyens qui seront ainsi fichés, de la ville de Toronto ou du gouvernement. Vous pouvez d’ailleurs lire Bianca Wilie sauter une coche très documentée dans ses articles de Medium
Sidewalk Toronto: A Hubristic, Insulting, Incoherent Civic Tragedy Part I, Part II,
Sidewalk Toronto: It’s Time for Waterfront Toronto 3.0 — Onward and Upward
Sidewalk Toronto: Amnesia, Willful Ignorance, and the Beautiful Anti-Democratic Neighbourhood of the Future
L’innovation, la prévoyance et l’ignorance
Depuis des années, nos gouvernements se gargarisent du mot « innovation ». Depuis peu, à celui-ci s’ajoutent ceux de « intelligence artificielle », « villes intelligentes » et « données ». Je suis tout à fait enthousiaste à l’avancement de la science, à l’innovation, à l’invention et à l’adaptation aux réalités technologiques qui arrivent à grands pas. J’ai même donné de mon temps, depuis des années, à l’idée d’un plan numérique pour le Québec. J’y militais entre autres pour le principe de « prévoyance », d’adaptation de la force de travail, de réseaux adéquats, de centres de données, de bases de données ouvertes et de plusieurs autres concepts fondamentaux qui nous permettront d’entrer de plain-pied dans le XXIe siècle. J’aimerais « qu’on voit venir » avant de se mettre collectivement dans la marde. Il me semble que la légifération des données est l’une des étapes cruciales à la protection du citoyen face à des enjeux de plus en plus présents et potentiellement inquiétants. Malheureusement, j’observe qu’outre un cercle très restreint d’initiées, c’est l’ignorance de ces avantages, périls et enjeux qui nous guettent…
Presque tous les hommes, frappés par l’attrait d’un faux bien ou d’une vaine gloire, se laissent séduire, volontairement ou par ignorance, à l’éclat trompeur de ceux qui méritent le mépris plutôt que la louange.
Machiavel
Vous pourriez aussi aimer
The trouble with informed consent in smart cities
Eight smart cities that are restoring privacy and empowering citizens with data
CITIES FOR DIGITAL RIGHTS
X-Road Explainer from Tolm on Vimeo.
Article publié le mercredi, 10 avril 2019 sous les rubriques Big data, cybersécurité, Droit et Internet, géolocalisation, Gouvernement électronique, hacking, politique et internet et transformation numérique.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Éric Caire, CAQ, cloud, données ouvertes, Loi favorisant la transformation numérique de l’administration publique, LPRPDE, PL-14, prédation des données, sidewalk toronto, villes intelligentes, x-road.
Cette semaine, dans l’article de La Presse, Les partis politiques mettent vos données personnelles à risque, selon le DGEQ, on pouvait lire :
Dans son rapport, rendu quelques mois plus tard, Me Reid évoque pour la première fois le risque que des pertes, des vols ou des accès non autorisés aux banques de données des partis exposent les données personnelles des millions de Québécois qui y sont fichés.
« Les partis politiques ne peuvent tenir pour acquis qu’ils sont à l’abri des cybermenaces contre le processus démocratique. Nous sommes préoccupés par cet enjeu et nous souhaitons agir d’une manière proactive afin de prévenir les conséquences sur la vie privée des électeurs. »
– Pierre Reid, directeur général des élections
Le DGEQ a certainement raison de s’inquiéter des risques d’intrusion et ou de vol des données personnelles des québécois que peuvent détenir les partis politiques. J’ajouterais à cette inquiétude, celle de l’obtention de la permission d’utilisation des données personnelles par les partis. Toutes les organisations se doivent d’obtenir, de documenter et de sécuriser de telles permissions sauf, les partis politiques. D’ailleurs, Vincent Marissal de Québec Solidaire souhaite un encadrement strict des partis politiques mais s’inquiète plutôt de pouvoir garder « la possibilité d’entrer en contact avec les gens ».
Le député de Québec solidaire Vincent Marissal a abondé dans le même sens. Il souhaite encadrer les partis « de la manière la plus solide possible ». Il a cependant souligné un autre passage du rapport du DGEQ, qui reconnaît leurs besoins particuliers.
« Il faut garder un équilibre pour assurer que nous soyons capables, comme parti politique, d’entrer en contact avec les gens, y compris pour faire de la sollicitation, y compris pour les inviter à des événements », a-t-il dit.
Je comprends monsieur Marissal de s’inquiéter de mettre en péril « le contact avec les gens de son parti ». Et pour cause, Québec Solidaire est champion du marketing électoral douteux. En effet, cette organisation politique, plutôt que de réellement proposer des législations et autres actions politiques qui ont réellement un impact sur la vie des citoyens durant les mandats de ses élus, privilégie les fameuses pétitions. Or, ces pétitions serviront d’outil de propagande électorale subséquente. Québec Solidaire profites de « trous dans la loi » sur la protection des renseignements personnels et les documents électroniques (LPRPDE) afin de spammer les électeurs en période électorale et ce, sans avoir eu la délicatesse d’obtenir leurs consentements préalables pour recevoir leurs publicité/propagande électorale car il s’avère que les associations et partis politiques sont exempts de la loi. Est-ce illégal ? Non ce n’est l’est pas. Est-ce éthique ? J’ai de gros doutes là-dessus.
Comme vous pouvez le voir dans cet exemple récent de PÉTITION POUR UNE ASSURANCE DENTAIRE PUBLIQUE, on demande aux gens leurs nom, prénom, courriel, téléphone, code postal et signature. On omet volontairement par contre de leur demander la permission d’utiliser ces données. Ça deviendra très utile en période électoral pour spammer les électeurs.

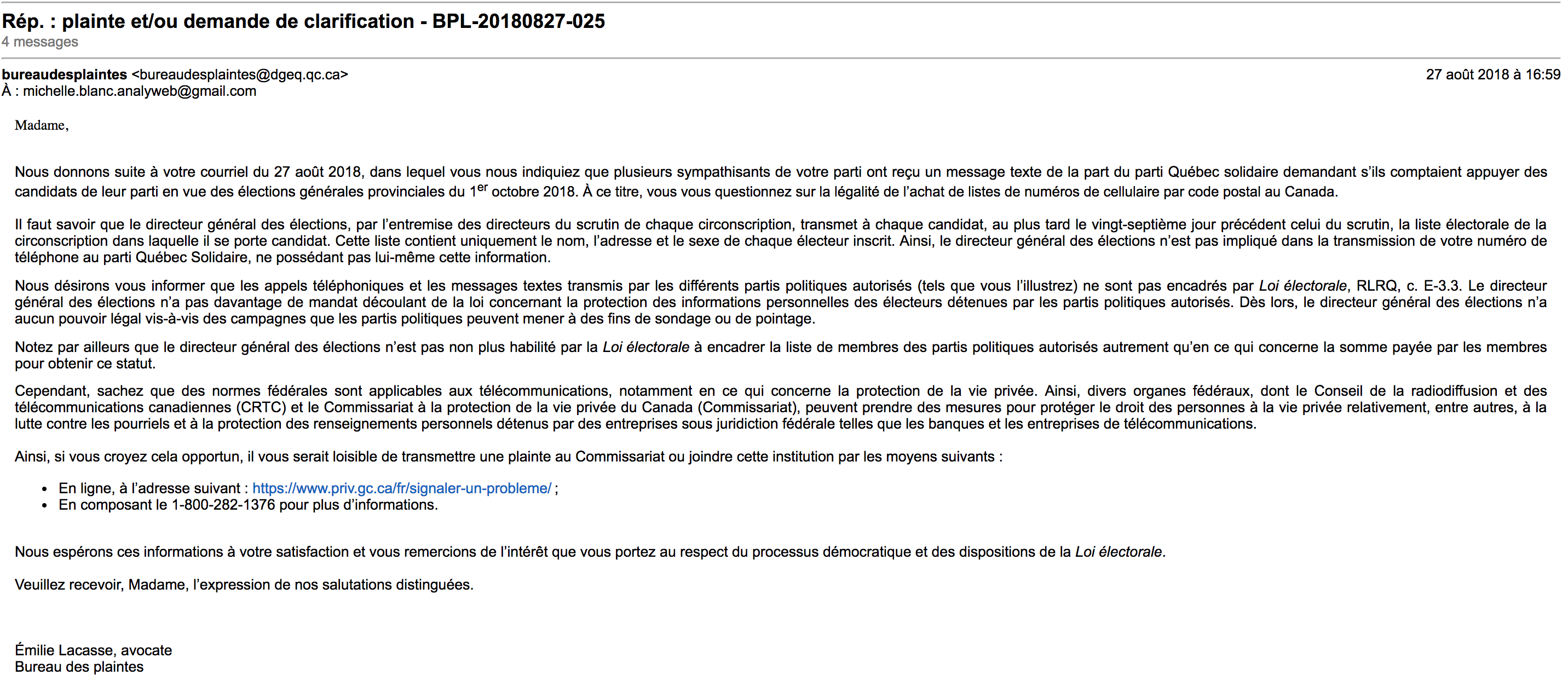
Étonnamment, lors de la dernière campagne électorale, plusieurs personnes de Mercier m’ont averti avoir reçu des messages SMS de Québec Solidaire durant les élections, sans pour autant avoir jamais signé l’une de leurs très nombreuses pétitions. Il faut savoir que de moins en moins de gens ont un téléphone filaire et qu’ils sont plutôt des usagers de mobiles. Or, pour avoir ces numéros de téléphones, il faut soit faire une pétition, soit acheter des listes de numéros de cellulaires par code postale. Or ces listes sont interdites au Canada, mais peuvent aisément être acheté aux États-Unis. Il est donc aisé de soupçonner que c’est ce qu’a fait Québec Solidaire pour être capable de rejoindre des électeurs qui n’ont jamais signé leurs pétitions. J’ai donc fait une autre plainte officielle au DGEQ. La réponse des porte-paroles de l’organisme est sans équivoque. Nous ne pouvons rien faire pour ce cas précis, allez voir ailleurs… Voici la réponse officielle du DGEQ.
Il est aussi bon de rappeler que Québec Solidaire a aussi profité des listes de données personnelles d’Option nationale (encore une fois sans l’autorisation des gens qui avaient fournis leurs informations à option nationale) de même que les listes de l’initiative Faut qu’on se parle.
Comme quoi, la réflexion du DGEQ sur les données personnelles que détiennent les partis politiques devrait sans doute inclure aussi une réflexion sur la nécessaire obtention de permission par les électeurs, d’utiliser ces mêmes données …
Article publié le vendredi, 7 décembre 2018 sous les rubriques cybersécurité, Droit et Internet, hacking, politique et internet et pourriels.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : DGEQ, Données personnelles, Québec Solidaire, spam.
Déjà, avec le USA Patriot Act, plusieurs gestionnaires qui ont à cœur la confidentialité des données personnelles et encore plus stratégiquement, la protection des secrets industriels et d’affaires choisissaient d’héberger les serveurs des organisations et entreprises au Canada, afin de limiter les ponctions extérieures à ces mêmes données. Mais avec le Clarifying Lawful Overseas Use of Data Act, mieux connu sous le nom de USA Cloud Act, les questions deviennent plus troublantes. Il a été largement documenté que nos lois de protection des données personnelles ne nous protègent pas de l’intrusion possible et effective du gouvernement américain. C’était d’ailleurs l’un des points que j’avais mis de l’avant dans le Plan numérique du Parti Québécois, lors de la dernière élection. J’y parlais de souveraineté numérique.
Doter le Québec de ses propres « fermes » de serveurs gouvernementaux, afin d’assurer sa pleine souveraineté en matière de données publiques gouvernementales.
À l’heure actuelle, il est impossible pour le gouvernement du Québec de garantir que les données sensibles des Québécois (information fiscale, de santé et autres) sont hébergées en infonuagique sur des serveurs québécois, ou selon les standards des lois québécoises.
Quelle est la controverse du Cloud Act?
(Traduit librement de ServerCloudCanada) Les autorités américaines peuvent désormais, grâce au Cloud Act, obtenir un subpoena obligeant les entreprises d’infonuagique américaines, à dévoiler aux autorités les données qu’ils requièrent. Cela s’applique à tous fournisseurs d’infonuagique américain qu’ils soient en sol américain ou dans d’autres juridictions comme disons, le Canada. Ainsi, le gouvernement américain s’arroge le droit d’accaparer des données dans des juridictions étrangères même si ces requêtes peuvent contrevenir aux lois de ces autres juridictions.
On peut donc en comprendre que même si les serveurs d’infonuagiques sont en sol canadien, ça n’aura aucune importance sur la protection des données qui sont hébergées chez des fournisseurs d’origines américaines. Qui plus est, il est même possible que les gouvernements et les propriétaires des données qui seront saisies par le gouvernement américain ne soient pas informés de ladite saisie comme le laisse entendre un article de The Verge, citant de nombreuses organisations de protection de la vie privée américaines.
A number of nonprofit groups oppose the bill on privacy grounds, including the American Civil Liberties Union, Electronic Frontier Foundation, Amnesty International, and the Open Technology Institute. The harshest criticism focuses on the new powers granted to the attorney general, who can enter into agreements with foreign countries unilaterally. Those agreements could potentially circumvent the protections of US courts. The act also wouldn’t require users or local governments to be notified when a data request is made, making meaningful oversight significantly harder.
Nonobstant cette nouvelle loi américaine, j’avais déjà fait état de la coercition de certains services de sécurité américains envers des entreprises d’hébergement canadiens dans mon billet Le chantage des services secrets américains pour contraindre les entreprises canadiennes à coopérer. Nos données sont donc de plus en plus en danger d’être scrutées, sans notre accord et c’est pourquoi il m’apparait judicieux, que les gouvernements du Québec et du Canada se dotent de leurs propres serveurs de données afin de protéger les données sensibles des Québécois et des Canadiens. C’est d’ailleurs le récent article L’identité des acheteurs de pot à risque L’adresse IP des Québécois qui consultent le site web de la SQDC passe par la Californie qui m’a mis la puce à l’oreille.
Vous pourriez aussi aimer
Les données personnelles des Québécois sont-elles déjà scrutées par les Américains
Le chantage des services secrets américains pour contraindre les entreprises canadiennes à coopérer https://www.michelleblanc.com/2013/06/14/primeur-le-chantage-des-services-secrets-americains-pour-contraindre-les-entreprises-canadiennes-a-cooperer/
Article publié le jeudi, 1 novembre 2018 sous les rubriques cybersécurité, Droit et Internet, hacking et politique et internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : cloud act, patriot act.
J’ai eu la chance de collaborer à la recherche et la rédaction d’une série d’excellents articles de mon ami et client Benoît Grenier (et de sa firme Parminc). Ces articles portent sur certaines des menaces les plus importantes qui pèsent sur les entreprises et leur PDG. Que ce soit les types de menaces informatiques, les conséquences de celle-ci, l’aveuglement volontaire de certains dirigeants, le manque de communication entre les parties prenantes ou même les faiblesses que certains fournisseurs de services-conseils en cybersécurité, ces articles illustrent éloquemment comment amorcer une réflexion en profondeur de ce qui pourrait permettre une croissance continue des entreprises, ou sa perte pure et simple. Je vous suggère fortement d’en prendre connaissance…
Les CEO et l’angle mort des cybercrimes
Les CEO et les cybercrimes, les solutions
Le CEO et les risques informatiques ou pourquoi se doter d’un CRO (Chief Risk Officer)?
MERCI à
https://parminc.com/
http://ginasavoie.com/
http://www.benoit-grenier.com/
http://www.csircorp.com/
http://nam-hoang.com/
Article publié le vendredi, 10 mars 2017 sous les rubriques cybercriminalité, cybersécurité, Economie des affaires électroniques, hacking et Terrorisme en ligne.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : cyber-criminalité, cybercriminalité.