Archives pour Big data
(Ce billet est la suite de Loi 25, le numérique, les cookies et comment s’y préparer? (Partie 1))
Depuis l’avènement de la RGPD européenne, nous avons pris l’habitude de voir apparaître sur les sites d’outre Atlantique, des popups nous demandant d’accepter (ou pas) l’utilisation des cookies (comme vous pouvez le voir dans la capture d’écran du journal LeMonde ci-bas). Les organisations québécoises et sans doute bientôt aussi canadiennes, devront aussi s’équiper de tels popup afin d’informer les internautes de la collecte des données que peuvent faire les cookies et requérir de manière proactive, leurs consentements. Ce consentement se devra d’être documenté dans la base de données à l’aide d’un système « opt-in » non coché d’avance. C’est-à-dire que c’est l’internaute qui devra cocher la section en question pour donner son consentement.
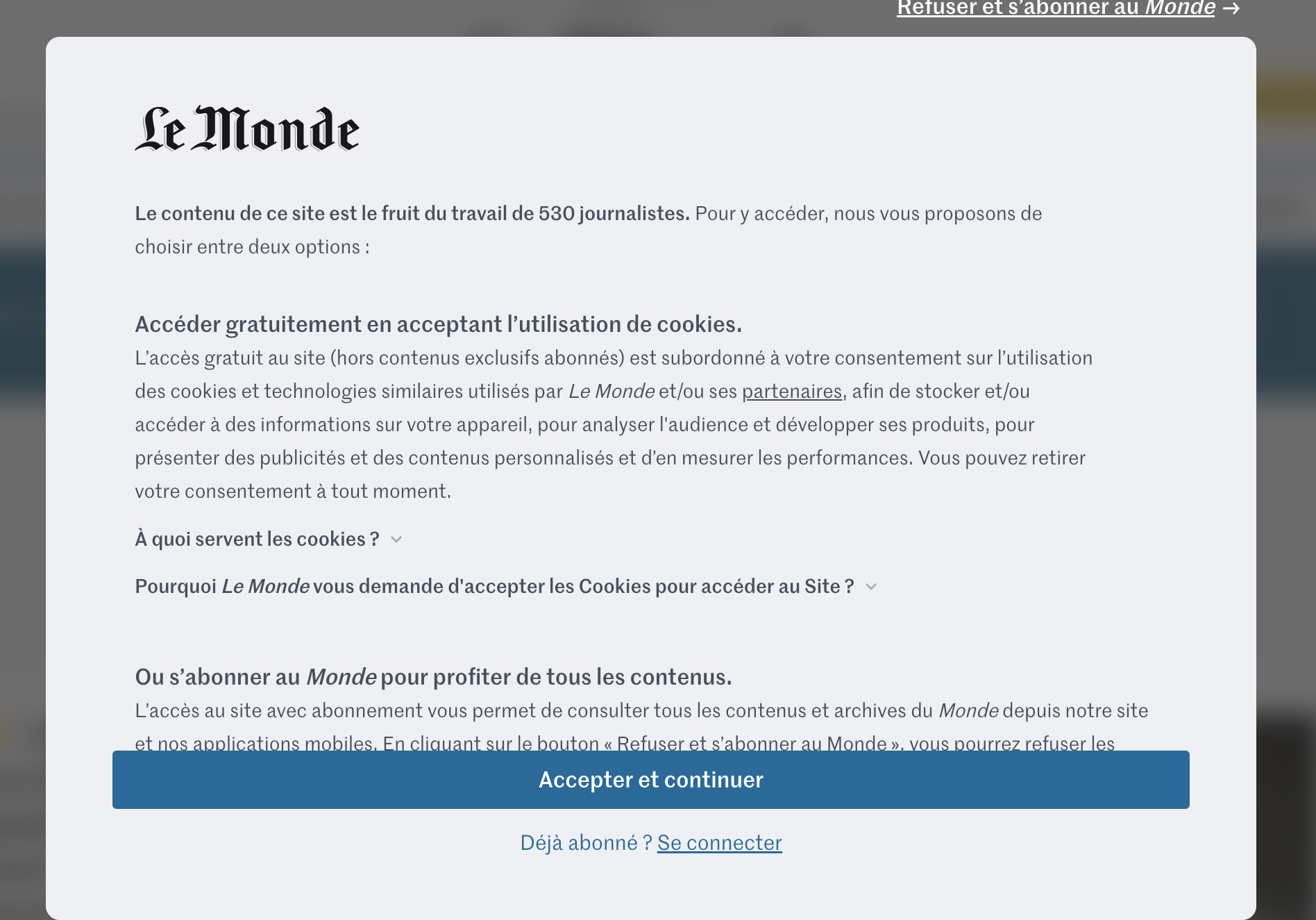
Il existe de très nombreux plugiciels que vous pourrez utiliser sur vos sites afin de facilement répondre à cette nouvelle obligation réglementaire. Par exemple le plugiciel WordPress Complianz, réponds déjà plusieurs réglementations de consentement internationales.
Complianz est une extension de consentement aux témoins RGPD/CCPA, qui soutient les RGPD, ePrivacy, DSGVO, TTDSG, LGPD, POPIA, APA, RGPD, CCPA/CPRA et PIPEDA, avec une notification conditionnelle des témoins et une politique de témoins personnalisée basée sur les résultats de leur analyse intégrée.
En plus de l’obtention du consentement, vous devrez
•Nommer et afficher publiquement un responsable de la protection des données de votre organisation (avec les coordonnées pour le rejoindre). Il sera responsable de la politique de la vie privée et pourras être rejoint par les internautes pour vérifier les données qui sont récoltées sur eux et demander des modifications à ces données le cas échéant.
•Vous devrez faire l’inventaire des types de données qui sont récoltés et identifier les incidents possibles associés à ces types de données, par ordre d’importance.
•Vous devrez aussi informer la Commission d’accès à l’information et toutes violation des données personnelles et de tout événement de hacking ou d’intrusion dans vos serveurs et instaurer un registre spécifique à cet effet.
En résumé, vous devrez
•obtenir le consentement à la collecte des données des visiteurs de votre site web.
•Offrir un moyen à ces visiteurs de connaître spécifiquement les données récolter sur eux, de les faire modifier ou carrément effacer.
•Expliquer clairement pourquoi les données sont récoltées.
Il est évident que ces nouvelles dispositions législatives vont générer des dépenses et du travail supplémentaire pour les organisations. Cependant, je trouve très pertinent qu’on s’intéresse de plus en plus à la collecte à tout vent des données personnelles et qu’on sécurise un tant soit peu, ces données, afin qu’elles ne puissent servir à des fins auxquels nous n’avons pas consenti.
Article publié le vendredi, 9 juin 2023 sous les rubriques Big data, cybersécurité et Droit et Internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Cookies, Loi 25, PIPEDA, Protection des données, RGPD.
Alors que j’avais développé un plan numérique pour le Parti Québécois lors des élections provinciales, j’avançais l’idée d’un passeport numérique. J’y crois toujours. Cependant, je suis aussi consciente que ça ne peut pas se faire n’importe comment et qu’à la base, le citoyen doit pouvoir contrôler ses informations personnelles. Ce n’est pas au gouvernement de contrôler ces informations, c’est au citoyen. Ces informations peuvent servir autant le bien que le mal et l’approche que le gouvernement doit prendre pour développer une telle identité peut faire toute la différence entre un outil facilitant la vie de tous et diminuant sensiblement les dédoublements d’information, la paperasserie, la fluidité des transactions avec les différents ministères voire l’efficacité des prestations gouvernementales et la réduction des coûts et la diminution de l’effectif des fonctionnaires pour faire la même chose que nous faisons déjà. Par contre, ça peut aussi servir à développer une société de surveillance, une tyrannie gouvernementale, une marchandisation de notre intimité et des informations les plus sensibles à propos de chacun de nous et l’établissement de « crédit social » à la chinoise faisant passer les devoirs avant les droits.
Je valorisais la technologie X-Road « pour assurer la confidentialité, l’intégrité et l’interopérabilité entre les parties à l’échange de données ». X-Road est d’ailleurs membre de la Digital Public Good Alliances dont l’un des buts est de favoriser le consensus à propos de l’échange des données en mettant de l’avant certains standards à cet effet.
6. Mechanism for Extracting Data
If the project has non personally identifiable information (PII) there must be a mechanism for extracting or importing non-PII data from the system in a non-proprietary format.
7. Adherence to Privacy and Applicable Laws
The project must state to the best of its knowledge that it complies with relevant privacy laws, and all applicable international and domestic laws.
9. Do No Harm by Design
All projects must demonstrate that they have taken steps to ensure the project anticipates, prevents, and does no harm by design.
9.a) Data Privacy & Security
Projects collecting data must identify the types of data collected and stored. Projects must also demonstrate how they ensure the privacy and security of this data in addition to the steps taken to prevent adverse impacts resulting from its collection, storage, and distribution.
Il ne semble malheureusement pas que ce sera la voie choisie par notre gouvernement. Récemment, notre ministre de l’économie valorisait l’idée d’étendre l’utilisation du passeport vaccinal à tous les commerces. Ce serait donc une sorte de cheval de Troie à l’identité numérique. Ça faisait ironiser le copain Michael Albo, scientifique des données, sur son profil LinkedIn :
Mais oui, étendez le passeport vaccinal à tous les commerces, cela permettra de traquer TOUS les déplacements des citoyens québécois et d’avoir encore plus de données à analyser pour étudier leurs comportements d’achat afin de les croiser avec d’autres sources de données.
Et comme les québécois aiment leur passeport vaccinal, vous avez bien raison de dire que “c’est un outil qui va probablement demeurer pour longtemps” même après la fin de la pandémie.
La gouvernance algorithmique et la surveillance totale sont à portée de main. Nous pourrons bientôt élaborer des algorithmes qui récompensent ou pénalisent directement les citoyens sur la base de données collectées et de leurs comportements d’achat.
Les personnes en surpoids qui se rendent trop souvent dans un fast-food ou les diabétiques qui achètent des crèmes glacées sont de dangereux irresponsables qui mettent en danger notre système de santé.
Nous allons “rééduquer” ces criminels avec leur consentement. Tout est pour le mieux dans le meilleur des mondes possibles.
#sarcasme #dystopie #quebec
D’ailleurs, en 2020 il affirmait en commission parlementaire que nous devrions encourager les pharmas à venir fouiller dans nos données médicales puisque « c’est une mine d’or ». Il semble qu’on soit très loin de « la recherche d’un consensus à propos de l’échange des données ». On valoriserait même la création d’une identité numérique par reconnaissance biométrique. Pourquoi utiliser une technologie d’identité numérique qui existe déjà, qui est utilisée ou analysée par les pays les plus en avance sur le numérique et respectueuse de la confidentialité des données alors qu’on peut tout réinventer, payer des sommes astronomiques pour le faire et « donner » l’accès à nos données les plus sensibles au plus offrant???
Et tant qu’à y être, pourquoi ne pas vendre aussi nos données fiscales en même temps que nos données de santé? C’est l’idée du siècle que valorise le gouvernement de la CAQ…
Article publié le jeudi, 3 février 2022 sous les rubriques Big data, politique et internet et X-Road.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
L’un de mes clients municipaux me demande d’analyser deux applications (et fonctionnalités) web qu’il aimerait implanter sur son site web. La première est une fonctionnalité québécoise d’alerte multiplateforme en cas de problématique comme un sinistre, feu de forêt, avis d’ébullition, risque de gel et autres. L’autre application en est une de soi-disant intelligence artificielle municipale (en faisant valoir le concept de ville intelligente) permettant de payer ses contraventions, répondre à un sondage, chatbot ou de carte numérique intelligente.
Le problème des données personnelles
Tout d’abord je spécifie que les deux fournisseurs de ces applications/fonctionnalités sont québécois et que leurs clients le sont presque exclusivement aussi. Je ne les nomme pas afin de ne pas compromettre ni ces entreprises ni ces municipalités (et de toute évidence afin de ne pas m’exposer à des poursuites préventives). L’un des deux fournisseurs n’a même pas de politique de vie privée sur son propre site. L’autre, a une fiche de recommandation peu enviable sur le AppStore d’Apple comme quoi, il est plein de bogues. De surcroit, les deux utilisent principalement l’architecture de sous-domaine de leur propre site afin de fournir la fonctionnalité, comme dans l’exemple: VilleXYZ.Fournisseurmédicocre.com . Ainsi, les usagers qui sont des payeurs de taxes de la municipalité sont en fait redirigés sur le site du fourniseurmédiocre.com qui a le contrôle complet de leurs données. À contrario, il existe des équivalents comme par exemple Onesignal qui grâce à une API, peut faire la même chose (et même plus) que la fonctionnalité d’alerte québécoise, tout en restant dans l’environnement de la municipalité. Il en va de même pour l’autre application.
Ce qui est ridicule avec ces cas et me rappelle la folie des CMS il y a 15 ans est que de petites boîtes se présentent comme ayant inventé le bouton à quatre trous dans un contexte d’une « demande en vogue et à la mode », alors que des alternatives open source, gratuites ou pratiquement gratuites et sécuritaires, existent déjà et que des clients québécois les payent sans (semble-t-il) avoir fait de diligence raisonnable et sans avoir évaluer les risques pour les données de leurs citoyens. C’est pitoyable…
Article publié le lundi, 13 décembre 2021 sous les rubriques Big data, Code-source libre, cybersécurité, géolocalisation, Gouvernement électronique, stratégie numérique et Technologies Internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Données personnelles, informatique municipale, onesignal.
Nous avons bien remarqué avec les restrictions de la Covid et l’essor du travail à distance que les routes étaient moins congestionnées et les bureaux vides dans les centres-ville. Mais ce n’est là qu’un des bénéfices tangibles de la numérisation de la société. Il en existe plusieurs autres.
Les mauvais calculs de l’idéologie verte
C’est en juillet 2019 qu’une étude de TheShiftProject « CLIMAT : L’INSOUTENABLE USAGE DE LA VIDÉO EN LIGNE » : LE NOUVEAU RAPPORT DU SHIFT SUR L’IMPACT ENVIRONNEMENTAL DU NUMÉRIQUE présentait que Le numérique émet aujourd’hui 4 % des gaz à effet de serre du monde, et sa consommation énergétique s’accroît de 9 % par an.
GreenMatters en faisait ses choux gras en disant
A study conducted by Maxime Efoui-Hess of the Shift Project concluded that watching a half-hour show through a streaming service like Netflix emits the equivalent of driving almost 4 miles, as reported by The New York Post. That half-hour requires electricity to run to the streaming service’s servers, and that electricity emits 1.6 kilograms of carbon dioxide into the atmosphere. It’s simple cause and effect.
Ces chiffres ont été démontés par the international Energy Agency
Drawing on our analysis and other credible sources, we expose the flawed assumptions in one widely reported estimate of the emissions from watching 30 minutes of Netflix. These exaggerate the actual climate impact by up 90 times.
L’analyse partielle
Autant The Shift Project qui a honteusement exagéré ses chiffres que the international Energy Agency qui les a remis dans leurs perspectives, ne parlent pas de l’énergie consommée avant Netflix par la myriade de produits et services complémentaires. On se souvient tous de Blockbusters. Or Blockbusters utilisait du pied carré pour ses commerces, les chauffait, utilisait des jaquettes de plastiques pour présenter ses dvd et ses cassettes qui elles aussi devaient être produites avec une quantité considérable d’énergie. Les consommateurs se déplaçaient aussi pour aller chercher et reporter les films qu’ils visionnaient et toute l’énergie nécessaire à ce processus ne semble pas avoir été mis en relief dans leurs études. Les verts semblent aimer parler d’environnement, mais lorsque vient le temps d’analyser l’environnement économique et énergétique, il est sans doute plus intéressant d’oublier l’écosystème pour ne cibler que l’élément qu’on veut démoniser.
Les autres bienfaits écologiques du numérique
La diminution drastique, voire la disparition du papier est sans doute l’élément qui nous vient rapidement en tête lorsqu’on songe aux bienfaits du numérique. On peut certainement aussi songer aux bienfaits environnementaux de la téléconsultation (médicale, psychologique, de gestion et autres) de l’agriculture intelligente, les améliorations aux chaines d’approvisionnement, à l’analyse même de la pollution, aux développements d’innovations comme des textiles intelligents, des voitures autonomes et autres. Les TIC ont donc un pouvoir d’optimisation d’à peu près toutes les composantes sociales et techniques et biologiques de notre univers. Ils sont cependant aussi une source considérable de pollution et d’utilisation des ressources énergétiques et naturelles (en particulier avec l’obsolescence programmée) qui doit être contrôlée et être diminuée drastiquement.
ICI donc deux écoles idéologiques s’affrontent. Celle pessimiste comme Florence Rodhainm auteure de “La nouvelle religion du numérique” :
La pensée magique accompagne le développement fulgurant du numérique dans nos sociétés. La prise de recul n’est plus autorisée. Pire, la pensée dominante voudrait nous faire accroire que le numérique est associé à l’écologique. Or, l’industrie des Technologies de l’Information et de la Communication est l’un des secteurs industriels les plus polluants et destructeur de la planète. Les injonctions à se diriger vers le « tout numérique » sont l’objet de manipulations, où les véritables motifs sont cachés : cachée la tentative de sauvegarder coûte que coûte un système qui nous entraîne vers le chaos, caché le fait que l’enfant est désormais considéré comme un consommateur plutôt que comme un apprenant… Se basant sur les travaux de recherche de l’auteure ainsi que ceux de l’ensemble de la communauté scientifique, cet ouvrage déconstruit cette pensée magique.
ou celle plus optimiste des auteurs de Impacts of the digital transformation on the environment and sustainability de Öko-Institut for the European Commission, DG Environment dont voici une partie de leur conclusion.
Page 78
Bieser and Hilty (2018b) conducted a systemic literature review on the indirect environmental effects of ICT. In their paper, diverse results on GHG emissions were identified. For example, the “SMARTer 2030” study by the Global e-Sustainability Initiative (GeSI), the ICT industry’s association for sustainability, expects that ICT applications could avoid up to 20% of global annual GHG emissions in 2030 (indirect effect), while the ICT sector causes only 2% of global GHG emissions (direct effect). In contrast, another study (Hilty et al., 2006) suggests that by 2020 the positive and negative effects of GHG emissions will tend to cancel each other out across the application domain. Bieser and Hilty (2018b) point out that these diverging results can be explained by differences in approaches: The old study by Hilty et al. (2006) is based on a dynamic socio-economic model, whereas the GeSi study uses a static approach, which is based on a much simpler model. Pohl and Finkbeiner (2017) also indicate that the GeSI study offsets actual direct effects of ICT against hypothetically avoided indirect effects in other fields. Further impacts which might lead to differences between potential and actual reduction were not considered. The inconsistencies in methodological approaches make it difficult to compare the results and also make
it difficult for decision makers to correctly interpret the results. Bieser & Hilty (2018a) point out that “Indirect impacts of ICT are often assessed by estimating the aggregated impact of several individual use cases. Such assessments face several methodological challenges, such as defining the baseline, estimating the environmental impact, predicting the future adoption of use cases, estimating rebound effects, or extrapolating from the single use case to society-wide impacts”.
Entretemps, des projets comme celui du Québécois Martin Bouchard qui avec son projet Qscale vise à récupérer l’énergie nécessaire pour alimenter ses centres de données, pour alimenter des serres de production agricole à longueur d’année et favorisant du même coup, l’autonomie alimentaire.
SOURCE: Pharaonique projet de techno et de serres gigantesques à Lévis
Article publié le mardi, 8 juin 2021 sous les rubriques Big data, Economie des affaires électroniques et Plan numérique pour le québec.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Florence Rodhainm, GreenMatters, Martin Bouchard, Qscale, the international Energy Agency, The Shift Project.
Dans un média qui se veut sérieux comme Direction informatique, il est surprenant de lire une infopub pro Amazon Web Services, déguisée en article de fond. Surtout que cette semaine, c’est la commission parlementaire qui discute justement de la possibilité de migrer les données personnelles des entreprises et citoyens québécois, sur de telles plateformes.
Je parle de l’article Avons-nous raison d’être frileux envers le cloud? Cet article est rédigé par Mark Nunnikhoven, vice-président de la recherche sur le cloud chez Trend Micro qui dit-on, serait “héros de la communauté AWS”.
L’article débute par écarter les joueurs québécois d’infonuagique en prétendant qu’ils seraient trop petits pour soumissionner en infonuagique. Pourtant, je connais Sherweb et MicroLogic qui seraient tout à fait capables d’aider l’hébergement infonuagique québécois.
Par la suite, l’auteur y va de demi-vérité. Il affirme que :
Malgré ces avantages évidents, j’entends encore des organisations brandir la menace du CLOUD act, ou d’autres mesures législatives pour justifier qu’elles ne peuvent construire dans le nuage. Il est tout à fait normal d’être réfractaire au changement et de repousser les idées nouvelles, surtout celles qui remettent en question les croyances de longue date.
Heureusement, le Commissaire à la protection de la vie privée s’est exprimé sur le sujet en déclarant que cette crainte n’est pas fondée. Si vous stockez et traitez des données canadiennes à l’extérieur du pays, votre devoir est d’informer vos utilisateurs de cette pratique. Mais comme des régions canadiennes sont disponibles depuis 2016, déplacer ces données à l’extérieur du pays ne devrait même plus faire partie de vos pratiques.
Il oublie cependant d’ajouter qu’avec le Cloud Act, c’est au fournisseur américain de défendre l’accès des données en sol Canadien si une requête de sécurité des agences américaines demandaient l’accès aux données hébergée ici. Ainsi donc, le gouvernement du Québec devrait s’en remettre à la bonne volonté et à l’expertise d’une tierce partie, en l’occurrence, le fournisseur américain, pour protéger nos données. Si on se fit à l’historique de protection des données de ces entreprises, disons qu’il y a de quoi avoir le poil qui nous retrousse sur les bras.
Ensuite, l’auteur nous parle de cryptage comme solution à une « peur non-fondée ».
Peu importe la situation, le cryptage demeure votre meilleur allié. Si vous cryptez vos données, en transit et au repos, il est impossible d’y avoir accès sans la clé de déchiffrement. Aucun fournisseur infonuagique ne vous obligera à leur remettre votre clé de déchiffrement. Vous décidez qui y a accès, et qui contrôle ces accès.
Encore une fois, par méconnaissance ou carrément par propagande commerciale, il oublie ici de dire que les fameuses clés de cryptage, sont loin d’être hermétique au gouvernement américain. En fait, le cryptage étant considérée comme étant aussi sensible que « de l’armement », aucun cryptage n’existe sans que le gouvernement n’y ait de « back door ». C’est ce que l’on nomme la « guerre de la cryptographie » ou « crypto wars » en anglais. Ainsi, comme on le note dans Wikipédia :
En 2009, les exportations de cryptographie non militaire depuis les États-Unis sont régulées par le Bureau of Industry and Security du département du Commerce 9. Certaines restrictions demeurent, même pour les produits grand public, en particulier en ce qui concerne les prétendus État voyous et les organisations terroristes. Le matériel de chiffrement militarisé, l’électronique certifiée TEMPEST, les logiciels cryptographiques spécialisés, et même les services de conseil cryptographique sont toujours soumis à licence9 (p. 6–7). De plus, l’enregistrement auprès du BIS est exigée par l’exportation de « produits de chiffrement pour le marché public, les logiciels et les composantes dont le chiffrement dépasse 64 bits » 10. D’autres éléments demandent aussi un examen par le BIS, ou une information du BIS, avant l’export dans la plupart des pays9. Par exemple, le BIS doit être informé avant la mise à disposition du public de logiciels de cryptographie open source sur Internet, encore que l’examen ne soit pas exigé 11. Ainsi, les règles à l’export se sont assouplies depuis 1996, mais restent complexes9.
D’autres pays, en particulier les parties à l’arrangement de Wassenaar 12, ont des restrictions similaires 13.
Comme quoi c’est bien beau pousser pour sa business, mais il y a des limites à peindre la réalité en rose…
Vous pourriez relire la conclusion de mon billet Les médias découvrent que BlackBerry de RIM n’est pas impénétrable, Petit réveil matinal (wake-up call)
Il est donc d’un impératif de « sécurité nationale » que les systèmes de cryptages soient limpides aux autorités gouvernementales et donc, qu’elles y ai accès. Les gouvernements étrangers vont faire des pieds et des mains pour avoir accès à tous systèmes de cryptages qui sont utilisés sur leur territoire et dont ils n’ont pas les clés. Le montréalais Austin Hill, le fondateur du défunt Zero Knowledge System a déjà été traité d’ennemi d’état parce qu’il avait développé un système de cryptographie personnelle impénétrable par les services secrets. Officiellement, son entreprise s’est redéployée pour offrir des services de sécurités aux entreprises de télécommunications parce que les consommateurs n’étaient pas prêts à payer pour l’anonymat sur le Web
Others aren’t convinced. Austin Hill, one of the founders of Zero-Knowledge Systems and now CEO of Akoha.org, says most people remain unaware of what happens to their information online — and unwilling to make sacrifices to protect it.
“Ask people if they care about the environment they’ll say yes, but they’re not willing to give up their SUVs,” says Hill. “Ask if they care about privacy, they’ll say yes, absolutely, but I will not take down my MySpace page with my 400 friends on it because that’s how I socialize. They’re very unaware that these pages get indexed, archived, and become part of their public record.
“I hate to say this, because I am a big fan of privacy,” Hill adds. “But I think as a society we are redefining our understanding of what ‘privacy’ means, and unfortunately not for the better.”
Mais des rumeurs persistantes soutiennent qu’il a plutôt été forcé à ce redéploiement par diverses pressions de natures étatiques…
Vous pourriez aussi aimé lire mes billets ou les articles
Le USA Cloud act et les problèmes d’intégrité et de confidentialité des données des Québécois
PL-14 sur la transformation numérique et les données personnelles, un pas en avant pour des km de retards
Cryptographie quantique…une réalité!
Les médias découvrent que BlackBerry de RIM n’est pas impénétrable, Petit réveil matinal (wake-up call)
Amazon déploie 20 lobbyiste au québec
Des cours gratuits d’Amazon aux fonctionnaires québécois
Amazon accusé de faire du «lobbyisme caché»
Article publié le mardi, 29 octobre 2019 sous les rubriques Big data, cybersécurité, Droit et Internet, Economie des affaires électroniques et politique et internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : AWS, cloud act, cryptographie, Direction informatique, Micrologic, sherweb.
Une cliente et amie qui travaillait pour une multinationale technologique a changé d’emplois pour travailler chez une start-up en Intelligence Artificielle. Elle n’y travaille plus outrée de ce qu’on lui a demandé de faire ou de ne pas faire. C’est que cette entreprise est fortement financée à même nos taxes (comme plusieurs start-up en IA), qu’une portion importante de ces subventions devraient aller en marketing et que très peu de cet argent se rend effectivement à ce poste primordial pour l’essor de l’entreprise. En outre, tout et n’importe quoi seraient de l’intelligence artificielle. C’est que c’est maintenant « le mot-clé » à la mode auprès des investisseurs et gouvernements et qu’il assure des retombées financières trébuchantes et sonnantes. Il suffit d’avoir un soi-disant algorithme pour se prétendre être en intelligence artificielle. D’ailleurs, personne ne pourras voir l’algorithme en question puisqu’il fera partie des « avoirs intangibles stratégiques » de l’entreprise. C’est drôlement opportun disons.
Sarcastiquement, Le Figaro titrait récemment, 40% des start-up européennes d’intelligence artificielle n’utilisent pas d’intelligence artificielle. On peut y lire :
Un leurre, joliment enrobé. Deux cinquièmes des start-up européennes d’intelligence artificielle n’utilisent en fait aucune technologie assimilable à de l’intelligence artificielle, d’après le rapport «The State of Ai» (l’état de l’IA) de la société d’investissement londonienne MMC Ventures. L’entreprise a mené l’enquête auprès de 2830 start-up européennes prétendant être spécialisées dans le domaine, en cherchant à en savoir plus sur les programmes d’intelligence artificielle utilisés à travers les entretiens avec leurs dirigeants et des recherches sur leurs sites Internet. Mais ils n’ont trouvé de preuves de l’utilisation réelle de ces technologies que pour 1580 d’entre elles. Malgré le manque d’intelligence artificielle dans leurs produits, 40% prétendent développer des programmes d’apprentissage automatique, utiliser des réseaux neuronaux ou encore faire de la reconnaissance d’image, note le Financial Times, qui rapporte l’étude.
Ça me rappelle la glorieuse époque 2005-2010 alors que nous investissions massivement en développement logiciel et que deux entrepreneurs sur cinq que je rencontrais, venaient de développer le nouveau CMS qui devait bouleverser la planète à $2000 de location par mois alors que WordPress qui est gratuit, existait déjà.
D’ailleurs, la conclusion de L’Institut de recherche et d’informations socioéconomiques (IRIS) dans le document Financer l’intelligence artificielle, quelles retombées économiques et sociales pour le Québec ? est plutôt ironique…
La mise en place d’un écosystème de l’IA exige une implication politique et financière considérable de la part de l’État. Ces investissements dans le secteur innovant des big data et de l’IA pour la relance de la croissance économique ont été justifié, en partie, par la crise économique mondiale de 2007-2008. Or, ces efforts sont menacés par l’incertitude liée aux retombées locales du capitalisme numérique, qui favorise plutôt la concentration des richesses et des résultats de la recherche entre les mains d’un nombre restreint d’acteurs. Si une réflexion éthique accompagne désormais le développement de l’IA, aucun espace institutionnel spécifique n’encadre pour l’instant les activités économiques des acteurs de ce secteur. De ce fait, non seulement les risques sociaux ne sont pas réellement minimisés, mais rien n’assure que des investissements publics majeurs se métamorphoseront en retombées collectives pour les Québécois·e·s.
Vous pourriez aimer lire mon billet de 2015
Ras-le-bol de l’innovation
Article publié le lundi, 21 octobre 2019 sous les rubriques Big data, Edito sans question, Innovation et politique et internet.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : IA, Intelligence artificielle.
C’est la semaine dernière que Monsieur Éric Caire, ministre délégué à la transformation numérique gouvernementale, a déposé le projet de loi 14 (PL-14) Loi favorisant la transformation numérique de l’administration publique. Selon le communiqué de presse du gouvernement, ce projet de loi vise à :
(…) à faciliter la mise en place de services numériques plus conviviaux et mieux adaptés aux besoins des citoyens. Il rend possible le partage d’information entre les ministères et organismes, lorsque la situation le requiert, pour améliorer la fluidité des services et simplifier l’accès aux solutions numériques gouvernementales.
Le projet de loi garantit la protection des renseignements personnels à toutes les étapes de la réalisation des projets numériques. Seuls les organismes publics spécialement désignés par le gouvernement seront autorisés à partager des renseignements personnels entre eux. L’utilisation de ces données est strictement limitée à la réalisation d’un projet d’intérêt gouvernemental, et ce, pour une durée fixe que la loi vient préciser.
C’est une étape importante et essentielle pour le développement éventuel de services gouvernementaux numériques dignes de ce nom et pour une saine prestation de service interministérielle. J’applaudis le gouvernement d’avoir fait ce premier pas. Par contre, à la lecture des prochains paragraphes, vous conviendrez comme moi qu’il s’agit en fait du strict minimum. J’imagine et je souhaite sincèrement que ce ne soit QUE le premier pas et que d’autres projets de loi viendront combler ce qui m’apparaît comme des lacunes importantes.
Les manquements évidents du PL-14
Depuis quelques années déjà, les entreprises sont soumises à la Loi sur la protection des renseignements personnels et les documents électroniques (LPRPDE) qui touchent les organisations et entreprises fédérales. En gros, ils doivent colliger les informations personnelles des consommateurs dans des banques de données spécifiques, nommer une personne responsable à la face du public, maintenir l’intégrité de ces mêmes données, offrir la possibilité aux consommateurs de vérifier l’exactitude de ces données et de les faire modifier si besoin et même de les effacer si tel est son choix. De plus, les entreprises seront scrutées à l’externe et s’exposeront à des amendes pouvant être très salées, s’ils ne se conforment pas correctement à cette loi fédérale. Voici d’ailleurs les 10 principes de cette loi.
-
- Responsabilité
- Détermination des fins de la collecte des renseignements
- Consentement
- Limitation de la collecte
- Limitation de l’utilisation, de la communication et de la conservation
- Exactitude
- Mesures de sécurité
- Transparence
- Accès aux renseignements personnels
- Possibilité de porter plainte à l’égard du non-respect des principes
Disons qu’à la lecture du PL-14, nous constatons que le gouvernement du Québec sera vraiment très loin de ces principes qui doivent assurer une certaine pérennité du consentement du citoyen, de la vérification de l’exactitude, de la limitation de la collecte, de la sécurité, de la transparence, de l’accès, de la permission et des mécanismes de plaintes et des conséquences éventuelles de ces plaintes.
Sur mon LinkedIn dans lequel je partageais cette loi, un abonné écrivit à propos de celle-ci
Suis allé lire le projet de loi. Que dire? Épeurant de vacuité par rapport à ce qui se fait ailleurs dans les pays occidentaux en matière de collecte et partage de renseignements personnels au sein des organismes publics. Rien sur le consentement éclairé des citoyens, rien sur les nouveaux renseignements personnels (biométrie et génétique). Où est le pendant pour protéger les citoyens des dérives de l’industrie privée. Seul point positif, le CT est responsable de l’application.
Par ailleurs, je comprends un peu le bourbier dans lequel se retrouve notre gouvernement. Afin d’être capable de satisfaire aux principes que notre gouvernement fédéral demande pourtant aux entreprises canadiennes, le gouvernement devrait à tout le moins avoir une gestion centralisée de ces données, ce qu’il n’a pas, et de gérer convenablement ces mêmes données, ce qu’il ne semble pas faire non plus. Dans le plan numérique du PQ que j’avais proposé, on parlait entre autre de l’architecture X-Road pour permettre de régler certains des problèmes de partage des données gouvernementales, tout en respectant la vie privée et le choix des citoyens de partager ce qu’ils veulent bien.
On parle ici de l’architecture X-Road. Créée en Estonie, l’architecture X-Road permet aux services publics du pays de s’interconnecter afin d’échanger leurs données pour faciliter la vie des citoyens. Ce modèle a permis une coopération plus poussée entre les organisations publiques et a réduit l’utilisation du papier de façon importante. En prime, les employés de l’État peuvent désormais se concentrer sur les tâches qui nécessitent des interactions humaines. Il s’agira, pour nous, d’observer ce qui se fait partout sur la planète et de retenir les solutions qui s’appliquent le mieux chez nous.
D’ailleurs, récemment le gouvernement suggérait de migrer ces données dans le « cloud » d’une des multinationales américaines avec un appel d’offres. En plus d’être un aveu d’échec cuisant de l’infrastructure des données actuelles, ça permettrait de « pimper nos données ». Lorsque j’écris ça, je ne me réfère pas à l’expression qui a le sens d’amélioration, mais plutôt à celui qu’on prostituerait nos données sensibles à un pimp qui par la suite nous ferait chèrement payer pour l’accès granulaire et intelligent de ces mêmes données. Ce qui est tout à fait scandaleux.
Données ouvertes
Dans ce document on ne dit strictement rien sur les données ouvertes ni sur la protection des données personnelles dans les contextes municipaux. On n’y parle pas non plus de l’intelligence artificielle, de la biométrie et de toutes les avancées aussi spectaculaires qu’inquiétantes que ces mêmes données permettent désormais.
Prédation des données sur le domaine public
Saviez-vous que présentement, certaines entreprises canadiennes et québécoises offrent aux municipalités canadiennes des mobiliers urbains intelligents? Ces mobiliers permettent entre autres d’enregistrer vidéo-voix-données, des usagers qui s’en servent et des passants qui circulent autour. Moi j’ai pogné un méchant buzz en apprenant ça. D’ailleurs, je sais que certains dirigeants TI de municipalités ont été outrés de tels avancés et de réaliser que ces informations étaient retransmises, sans filtres, aux fournisseurs qui proposaient ces mobiliers. Il en est de même pour les feux de circulation intelligents qui scannent les adresses MAC qui se trouvent dans un rayon de 200 mètres de ces feux, puis revendent ses informations au plus offrant, sans que personne ne s’en inquiète. Il me semble qu’il y a là une méchante matière à légiférer. L’un des exemples éloquents des dérives possibles de ce laisser-aller législatif au profit de « bienfaiteurs intelligents et de fournisseurs de gugus de données » est l’exemple récent de Sidewalk Toronto. Un projet de ville intelligente parrainée par la bienfaitrice Alphabet, maison mère de Google. Ce projet est une « expérience » de l’établissement d’un quartier intelligent en bordure du Lac Ontario à Toronto. Il permettra à Google de recueillir et de gérer les données faciales, télémétriques, de circulation et de toutes autres données qu’il jugera importantes, sans l’autorisation des citoyens qui seront ainsi fichés, de la ville de Toronto ou du gouvernement. Vous pouvez d’ailleurs lire Bianca Wilie sauter une coche très documentée dans ses articles de Medium
Sidewalk Toronto: A Hubristic, Insulting, Incoherent Civic Tragedy Part I, Part II,
Sidewalk Toronto: It’s Time for Waterfront Toronto 3.0 — Onward and Upward
Sidewalk Toronto: Amnesia, Willful Ignorance, and the Beautiful Anti-Democratic Neighbourhood of the Future
L’innovation, la prévoyance et l’ignorance
Depuis des années, nos gouvernements se gargarisent du mot « innovation ». Depuis peu, à celui-ci s’ajoutent ceux de « intelligence artificielle », « villes intelligentes » et « données ». Je suis tout à fait enthousiaste à l’avancement de la science, à l’innovation, à l’invention et à l’adaptation aux réalités technologiques qui arrivent à grands pas. J’ai même donné de mon temps, depuis des années, à l’idée d’un plan numérique pour le Québec. J’y militais entre autres pour le principe de « prévoyance », d’adaptation de la force de travail, de réseaux adéquats, de centres de données, de bases de données ouvertes et de plusieurs autres concepts fondamentaux qui nous permettront d’entrer de plain-pied dans le XXIe siècle. J’aimerais « qu’on voit venir » avant de se mettre collectivement dans la marde. Il me semble que la légifération des données est l’une des étapes cruciales à la protection du citoyen face à des enjeux de plus en plus présents et potentiellement inquiétants. Malheureusement, j’observe qu’outre un cercle très restreint d’initiées, c’est l’ignorance de ces avantages, périls et enjeux qui nous guettent…
Presque tous les hommes, frappés par l’attrait d’un faux bien ou d’une vaine gloire, se laissent séduire, volontairement ou par ignorance, à l’éclat trompeur de ceux qui méritent le mépris plutôt que la louange.
Machiavel
Vous pourriez aussi aimer
The trouble with informed consent in smart cities
Eight smart cities that are restoring privacy and empowering citizens with data
CITIES FOR DIGITAL RIGHTS
X-Road Explainer from Tolm on Vimeo.
Article publié le mercredi, 10 avril 2019 sous les rubriques Big data, cybersécurité, Droit et Internet, géolocalisation, Gouvernement électronique, hacking, politique et internet et transformation numérique.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Éric Caire, CAQ, cloud, données ouvertes, Loi favorisant la transformation numérique de l’administration publique, LPRPDE, PL-14, prédation des données, sidewalk toronto, villes intelligentes, x-road.
C’est en lisant Why Websites Still Can’t Predict Exactly What You Want de Harvard Business Review que ça m’a frappé. Les entreprises numériques ont encore bien des croûtes à manger avant d’avoir une personnalisation en ligne, digne de ce nom. Je vous en avais déjà parlé dans mon billet Certains ratés de la personnalisation numérique.
Toujours est-il que dans l’article de HBR, l’auteur met le doigt sur une possible explication de ces lacunes de personnalisation.
All that data and still an underwhelming result. What’s happening here? It seems that it’s a matter of how the companies position personalization. They regard it as a tool for upselling–they want to push us out of our comfort zone, to buy new things, and to buy more things. To achieve that goal, the companies can’t just look at one’s historical browsing or purchase patterns. Instead, data scientists look for traits in similar customers. When you position personalization this way, you build algorithms that are based on finding variables.
En effet, depuis l’avènement de « la filtration collaborative » d’Amazon, (c’est-à-dire ceux qui ont aimé ce produit ont aussi aimé tel, tel et tel autre produit, ce qui représente tout de même plus de 50% des ventes d’Amazon) les entreprises se sont confinés à l’analyse prédictive. Il s’agit donc d’une tentative d’upselling (concrétiser la 2e vente). Par contre, très peu, voire aucun effort n’est encore mis sur l’historique de consommation, ce que l’on nomme les données invariables. Comme l’auteur le mentionne, sur Amazon, si ça fait déjà quelques achats que je fais pour acquérir des souliers de grandeur 13WW, il y a de fortes chances que si je magasine encore des chaussures sur Amazon, ce le sera pour la même grandeur de chaussure. Pourtant, cette simple donnée invariable, qui améliorerait très sensiblement mon expérience usager en ligne, n’est toujours pas utilisée.
Pourquoi faire simple lorsqu’on peut faire compliqué?
C’est un peu la conclusion de l’auteur de l’article. Ce n’est pas sexy de travailler sans algorithme et il n’y a pas de valorisation pour les geeks qui les développe. Ça faciliterait par contre grandement la vie des clients internautes et les fidéliserait aussi sans doute à la marque
In short, these kinds of easy wins aren’t sexy enough for data scientists. And maybe they fear their effort would go unnoticed if we can get better personalization without teams of PhD’s spending three years to create hundreds of algorithms.
Data scientists are vital to the future economy and advanced algorithms are an extremely important part of their work. But from a market-facing perspective, simplicity and quick wins should be part of the data science toolbox.
Article publié le lundi, 7 juillet 2014 sous les rubriques Big data, Commerce électronique : articles, Commerce de détail en ligne, Innovation, Marketing 2.0, Stratégies de commerce électronique, Technologies Internet et Web 2.0.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : Amazon, filtration collaborative, Harvard Business Review, longue traîne.
Mise en contexte :
Comme vous le savez déjà, je me suis exprimée pour La charte des valeurs québécoises et je faisais partie des 20 Janette qui ont signé la lettre de Madame Janette Bertrand, qui elle-même a généré un mouvement massif d’appui populaire.
Mais cela étant dit, ça ne m’empêche pas d’être « neutre » et « objective » lorsque vient le temps d’analyser ce qui s’est dit sur les médias sociaux. Par ailleurs, l’analyse que je vous partage plus bas a été réalisée par deux collaborateurs d’importance, qui n’ont aucun enjeu personnel ou corporatif avec les discussions autour de la Charte. Il s’agit de SAS Canada (client de longue date et SAS est le pionnier de l’analyse de données et de l’analyse prédictive) et de Inbox, entreprise française spécialiste de la connaissance clients et usagers et du big data également implantée au Canada et ayant développé un complexe algorithme sémantique francophone permettant de faire de l’analyse de sentiment en français (ce qui est très rare parce que la majorité des outils disponibles sont anglophones et n’ont pas la capacité d’analyse de sentiments et du prédictif).
SAS Canada et Inbox ont l’habitude de travailler entre-autres avec des grosses boîtes financières, d’assurances ou de commerce de détail, de médias internationaux et du secteur public. Ce sont eux entre autres qui font de la détection de fraude par l’analyse de très grands volumes de contenus (Big Data) pour les cartes de crédit ou les assurances. Grâce à sa technologie, Inbox a été la première source à identifier la fin de la récession en France, deux semaines avant tout le monde. Tout ça pour vous dire que lors d’une discussion avec SAS et Inbox sur la difficulté d’expliquer l’importance du « big data » à des clients potentiels (parce que ce n’est pas sexy) je leur propose d’utiliser leur technologie pour un sujet chaud de l’heure (comme la charte des valeurs québécoises). Ainsi, les gestionnaires pourront facilement comprendre en extrapolant, comment eux-mêmes pourraient bénéficier de la compréhension de ce qui se dit sur les médias sociaux, pour leur propre organisation. Voici donc le rapport d’analyse de SAS Canada/Inbox sur les discussions sur les médias sociaux à propos de la charte des valeurs.
Pour comprendre les graphiques
Voici une analyse de sentiment “Big Data” de différents thèmes discuté sur les médias sociaux (Facebook, Twitter, blogue) à propos de la Charte des valeurs québécoises. Remarquez en abscisse “LE VOLUME DES MESSAGES” et en ordonnée “L’INDICE DE POSITIVITÉ DU MESSAGE” qui est aussi appelé “analyse de sentiment. Ceci est une version préliminaire de l’analyse, qui est toujours en cour. Étant donné que le projet de loi du PQ risque d’être déposé dans les prochains jours, un grand volume de commentaires continuera d’alimenter les discussions médias sociales. Pour comprendre comment se fait l’analyse de sentiment, je vous dirai qu’avec l’algorithme d’Inbox un terme comme « crise » contiendra 1000 paramètres différents afin de déterminer le contexte de ce mot spécifique et de savoir si on parle par exemple « d’une crise économique » ou si plutôt « il a pété une crise ». Leur analyse de sentiment est donc fiable à 85% et la marge d’erreur est la même pour tous. Aussi, si par exemple un twitt parle de Dalila Awada et qu’il contient un hyperlien vidéo, comme l’hyperlien et le vidéo ne seront pas analysés, ce ne sera que le contenu de la mise en contexte précédant l’hyperlien qui sera pris en compte.
Le corpus
Les sources suivantes ont été analysées:
• Twitter
• Facebook
• Forum Yahoo
• JM : Journal du Montréal avec 3 sous-forums:
• http://blogues.journaldemontreal.com/politique/,
• http://blogues.journaldemontreal.com/droitdecite/,
• http://www.journaldemontreal.com/auteur/richard-martineau )
• LP : LaPresse avec 3 sous-forums :
• http://blogues.lapresse.ca/boisvert,
• http://blogues.lapresse.ca/edito,
• http://blogues.lapresse.ca/avenirmtl )
Mon analyse
J’attire votre attention sur les diapositives 3, 4 et 5. Vous remarquez qu’elles sont des portraits des discussions médias sociaux des 14, 21 et 31 novembre octobre. Vous remarquerez sans doute aussi qu’au 14 octobre, la majorité des mots clés, personnalités et organisations associés au débat de la charte sont perçus très négativement. Par contre, après le 21 octobre, ces mêmes termes (en plus de celui de # Janette qui commence à apparaitre), font passer plusieurs mots du côté positif. Vous remarquerez aussi qu’étrangement, Charles Taylor est vu plus négativement qu’Adil Charkaoui, mais que son collègue Gérard Bouchard jouit d’une négativité beaucoup moins grande. Vous observerez sans doute aussi que le Conseil du Statut de la femme est l’entité la plus méprisée et que la CQCI est l’organisation qui récolte la plus positive des mentions sur les médias sociaux, mais vous observerez que le volume des messages qui y est associé est somme toute insignifiant comparativement aux Janette par exemple. Observez aussi que Les Anti-Charte et les pro-charte sont tous deux du côté négatif des discussions, que le volume des discussions est somme toute équivalent, mais que les pro-charte sont beaucoup moins détestées que les anti-charte. Finalement, les inclusives ont 10 fois moins de mentions que les Janette, et elles sont à peine perçues plus positivement que les Janette et elles sont toutes deux du côté positif des discussions. Je pourrais continuer de vous faire mes observations, mais vous comprenez sans doute maintenant le principe et je ferai cette discussion de vive voix la semaine prochaine lors d’une conférence au Salon BI. Donc bonne lecture et bonne analyse ☺
MAJ
Ce billet a été repris intégralement par le HuffingtonPost
Article publié le mercredi, 6 novembre 2013 sous les rubriques Big data, Blogue, Facebook, Médias auxquels je collabore, Médias sociaux, Medias et Internet, Moteurs de recherche et référencement de sites Web, Relations publiques Internet, Technologies Internet et Twitter ou le microblogging.
Vous pouvez suivre les commentaires sur cet article via ce fil RSS.
Vous pouvez laisser un commentaire ci-dessous ou un rétrolien à partir de votre site.
Libelés : analyse de sentiments, Charte des valeurs québécoises, Inbox, Janette, SAS Canada.










